@WeiXiao: Też możesz zrobić to bez wyjątku, kiedy deskryptor pliku po otwarciu ma wartość -1.
0
2
@PerlMonk:
-1. Najgorsza obsługa błędów pod słońcem. Jeszcze długo będzie się odbijać czkawką. Aczkoliwek, w czasach kiedy projektowano C i unixa to cały computer science był jeszcze młody i głupi, a sprzęt był kiepski - pretensji mieć nie można.
1
Krolik napisał(a):
Nie mogę się zgodzić, że próba otwarcia nieistniejącego pliku powinna rzucać wyjątkiem. Ta sytuacja jest poza kontrolą aplikacji, nie da się przed nią zabezpieczyć jak przed dzieleniem przez zero, więc to powinna być standardowa ścieżka do obsłużenia, tak jak każde inne nieprawidłowe dane od użytkownika.
Nie chcę się zgodzić, że (wyżej)
Otwarcie pliku na dysku to standardowe IO.
Otwarcie pliku na pendrive to standardowe IO
Otwarcie pliku w chmurze to standardowe IO
Z punktu widzenia aplikacji to sięgamy do abstrakcji (IO) więc operacja na pliku to operacja IO
Czy możemy sprawdzić, że mamy internet? Możemy.
Czy możemy sprawdzić, że mamy plik w chmurze? Możemy.
Czy internet może być LTE? Może.
Czy internet LTE po wejściu do sklepu na parterze betonowego apartamentowca zdechnie do 2G (to mi się zdarza w W-wie). Może.
Czy sytuacja, że da się przesyłać pakiety, bo jest 2G ale takiego "internetu" to jakby nie było może być? Może.
To w którym momencie (drabina warunków) sytuacja jest jeszcze standardowym IO (jak z czytaniem z dysku w smartfonie) którą da się przewidzieć i obsłużyć a kiedy to już sytuacja wyjątkowa?
0
@jarekr000000: Nie zgadzam się. Nie masz tu pierdyliarda try- catch jak w Javie. Sprawdzasz czy był błąd kiedy chcesz. W Javie czasem wręcz wymusza się try- catch i to wcale nie poprawia jakości kodu; Nie masz ifologii jeśli nie chcesz.
int file = open(...);
if (file < 0) {
exit(1);
}
Ot całe sprawdzenie.
2
Dobra, przyznam szczerze że nie czytałem całej dyskusji, ale w czym jest lepsze rzucanie wyjątków od Either<ParseError, LocalDate> zwracanego z LocalDate.parse(String date); ?
Pisałeś że czasami jest to zbyt niski poziom i nie wiadomo czy obsługiwać. No to jak to jest rzeczywiście jakiś wyjątek to robisz either.orThrow(() -> new IllegalArgumentException());
@TomRiddle
3
@PerlMonk:
Problem jest taki, że ten kod się też kompiluje
int file = open(...);
char ch = getc(file);
A nie powinien. Tak się właśnie rodzą luki w bezpieczeństwie, CVE i dramaty jakich w kodzie C jest pełno.
@TomRiddle
Co do performancu i wyjątków. Miałem dwa razy w życiu przypadek, że wyjątki zabijały maszyne na produkcji. Bo jakaś biblioteka używała sobie szczęśliwie Exception oriented programming. W jednym przypadku trzeba było przepisac kawałek biblioteki (przesławne strutsy zreszta), w drugim firma zmieniła JVM na taki, który lepiej sobie radził z dziesiątkami tysięcy exceptionów rzucanych na sekundę (ale nadal to było 30-50% procka i było męczące).
Problemy z monitoringiem / narzędziami, które alergicznie reagują na tony rzucanych exceptionów to inny propblem (@somekind wspomniał). Jest smutne, jak nie możesz normalnie monitorować aplikacji i mieć np. ładnego profilingu - bo wyjątki wszystko kompletnie zaciemniają - nawet jeśli nic nie leci do loga.
Jeśli robisz api / biblioteke to dobrze jest dać szansę korzystania z niego, bez odwoływania się do wyjątków (podałem regułę). Jak ktoś będzie chciał sobie zrobić wyjątek - to sobie zrobi, można to nawet zautomatyzować. Taki Either / get to bardzo dobry przykład, dostajesz eithera, który nie jest wyjątkiem, chcesz mieć wyjątek - robisz na nim get() bez sprawdzania czy jest dobry - i juz. Oczywiście, my maniaki fp, nie robimy get() nigdy - ale to inna historia.
0
Krolik napisał(a):
Nie mogę się zgodzić, że próba otwarcia nieistniejącego pliku powinna rzucać wyjątkiem. Ta sytuacja jest poza kontrolą aplikacji, nie da się przed nią zabezpieczyć jak przed dzieleniem przez zero, więc to powinna być standardowa ścieżka do obsłużenia, tak jak każde inne nieprawidłowe dane od użytkownika.
Czyli jak? Kody błędów?
Próba otwarcia pliku może się nie powieść na milion sposobów.
Przykładowy zbiór kodów: https://docs.microsoft.com/en-us/windows/win32/debug/system-error-codes--0-499-
(bardziej ogólny, ale dużo się pokrywa)
Próba otwarcia nieistniejącego pliku to tylko jeden z scenariuszy dla funkcji otwarcia pliku.
I nawet w tym scenariuszu jest kilka możliwych błędów:
- nieznany system plików
- niedostępny system plików
- nieistniejący katalog
- nazwa pliku ma nieprawidłowe znaki
- plik nie istnieje
- plik istnieje ale jest ukryty itd.
2
Chodziło mi o to, że nie możesz się zabezpieczyć przed błędem otwarcia pliku PRZED otwarciem pliku. Możesz dopiero to zrobić PO próbie otwarcia. Nie jest to zatem błąd programu, że próbuje czytać niedostępny plik.
W niektórych językach przyjęło się, że mechanizm wyjątków / panic / abort powinien być stosowany do sytuacji, których program może uniknąć i które są błędami programu - np. zły indeks tablicy, dzielenie przez zero, dereferencja nulla, overflow numeryczny, zapis pod nieistniejący adres pamięci itp. W Javie tę rolę pełnią z kolei wyjątki unchecked. W te kategorię wypadają też błędy krytyczne po których nie ma sensu wykonywać programu - np. spowodowane awarią procesora.
Natomiast mamy jeszcze druga kategorię błędów - błędy których nie da się uniknąć, bo wynikają z rzeczy których program nie kontroluje, a które trzeba obsłużyć. Np. brak pliku albo wspomniany wyżej "brak internetu". I do tego kodu błędów są jak najbardziej ok, przy czym lepiej jest jeśli język ma mechanizm sum typów czyli np. Either / Try / Result itp, bo wtedy nie da się nieświadomie zapomnieć o obsłudze takiej sytuacji. W niektórych językach do tego służą wyjątki checked.
Co do tego czy zwracać przez wynik czy wyjątki to mnie osobiście bardziej się podoba zwracanie przez wynik, bo w ten sposób można np. reprezentować całą kolekcję błędów np. mogę mieć metodę która zwraca Vec<Result<X, Error>>, a z wyjątkiem tego już nie zrobię. I potem można stosować różne fajne transformacje na takim wyniku.
3
@TomRiddle: masz rację, cała sprawa się rozwlekła, a my obaj w sumie piszemy to samo od paru postów, tylko inaczej to ubieramy w słowa. Dlatego - tak, jak proponowałeś - zrobię taki mini-reset i napiszę w krótkiej wersji **moje **podejście do tematu.
- Rzucanie wyjątków jako takie powinno być stosowane w sytuacjach awaryjnych.
- Rzucanie wyjątków mogę zrozumieć jako formę odpowiedzi w przypadku wywołania czegoś zewnętrznego - gdy ta funkcja/biblioteka napotka problem i chce zwrócić informację do podmiotu wywołującego, że nie udało się wykonać zadania, ALE
- Takie przekazanie informacji zwrotnej można osiągnąć na inne sposoby - były wymieniane w tym wątku (chociażby jakiś kod błędu, klasa opakowująca error, mechanizmy typowe dla niektórych języków typu either itp.)
-
NIE PODOBA MI SIĘ
exception driven development- czyli w przypadku dawanego jako przykład konwertera ścieżka w stylu "daję coś do convertera, on jeśli zwróci wyjątek to przekazuję do innego convertera, jeśli on zwróci wyjątek to do kolejnego itp.". - Poszerzając poprzedni punkt - od tego jest logika aplikacji, żeby sprawdzić, czy dane są odpowiedniego typu, albo przy dzieleniu czy dzielnik jest różny od zera. Dopiero jeśli jestem przekonany, że dane są OK, to je pcham dalej
- Kontynuując pkt. 5 - jeśli konwerter dostanie dane nieodpowiednie to może rzucić wyjątek (albo zgodnie z pkt. 3 - przekazać informację zwrotną w inny sposób) ALE to nie jest element zwykłego wykonania programu, tylko sytuacja naprawdę awaryjna - czyli taka, w której mimo zachowania ostrożności, coś poszło niezgodnie z założeniami
Łamie warstwy abstrakcji, łamie hermetyzację, sprawia że więcej niż jeden obiekt wie o PDF'ach
Nie zgadzam się.
Tak naprawdę to ja (jako obiekt wywołujący) nie muszę znać wewnętrznego mechanizmu działania obiektu/funkcji/biblioteki, którą wywołuję. Zamiast odpalić converter.isPDFValid() (co po części może się zgadzać z tym, co napisałeś - jest zaglądaniem we wnętrzności konwertera, chociaż na bardzo wysokim poziomie abstrakcji, nie mam dostępu do samego PDF, a jedynie odpytuję, czy jest on OK) można dać converter.isReadyToProccess() i wtedy w zależności od odpowiedzi - albo każę uruchomić konwersję, albo odpalam inną procedurę. Czyli - jeśli załadowałem jakiś plik do konwertera, a mimo tego konwerter mi mówi, że nie jest gotowy do działania, oznacza to, że tego pliku nie da się w ten sposób przetworzyć.
Idąc dalej - jeśli konwerter powie "OK, mogę działać", a ja mu nakażę działanie, a mimo tego podczas konwersji się wychrzani (bo np. plik PDF będzie w środku skopany) to wtedy jak najbardziej rozumiem rzucenie wyjątku.
Jest to sytuacja, w której w normalnej logice sprawdziłem, że plik został dostarczony, wydawało się że jest poprawny, ale podczas jego przetwarzania coś się wykrzaczyło. To jest właśnie idealny przykład sytuacji wyjątkowej, w której całkowicie się zgadzam z rzuceniem wyjątku. Ale to jest sytuacja wyjątkowa, do której zrobiłem wszystko co mogłem, żeby nie doprowadzić, a mimo tego coś się wywaliło. Nie używam wyjątków do sterowania przebiegiem aplikacji, a jedynie do łapania sytuacji niespodziewanych/wyjątkowych.
Znowu argumenty nie merytoryczne. Posługujesz się określeniami "machina wyjątków" oraz "jeden prosty if", tak żeby nadać nacechowanie tym elementom.
[...]
Jestem niemal przekonany, że w wielu aplikacjach znajdzie się 100 bardziej ważnych punktów do optymalizacji niż używanie wyjątków.
Po części masz rację, pewnie da się zrobić lepsze optymalizacje/refactor. Ale nie zgadzam się z podejściem, że skoro są większe rzeczy do zrobienia, to można olać mniejsze. To jak z porzadkami w domu - możesz mieć syf w salonie, ale posprzątanie jedynie parapetu i szafki już trochę ten bałagan zmniejszy ;)
A co do tego, że są to uwagi niemerytoryczne - nie zgodzę się. OK, ja nie jestem jakimś autorytetem, ale zobacz co pisali inni, chociażby:
@jarekr000000 - Rzucanie wyjątkami a "zwykłe" zaprojektowanie obsługi błędu
@somekind - Rzucanie wyjątkami a "zwykłe" zaprojektowanie obsługi błędu
@MarekR22 - wyjątki kompletnie bez sensu - C++ i obsługa wyjątków jest ~40 razy wolniejsza od standardowego zwijania stosu [...] koszt zwijania stosu podczas wyjątków jest absurdalny, dlatego ograniczyłbym ich użycie do sytuacji literalnie wyjątkowych
@nalik - wyjątki kompletnie bez sensu
Poza tym parę linków spoza 4P:
https://theburningmonk.com/2011/09/the-cost-of-throwing-exceptions/
https://php.watch/articles/php-exception-performance
Throughout all PHP versions tested, the try/catch blocks themselves have relatively small performance impact. However, throwing an Exception, which requires PHP to collect the stack trace and create an Exception object can be costly, and is up to 9 times slow.
Generally, the use of exceptions for control flow is an anti-pattern [...] Exceptions are, in essence, sophisticated GOTO statements
Rozumiem, że możemy mieć inne podejście, możesz nie zgadzać się z tym, co napisałem (albo do mnie może nie trafiać Twoja argumentacja), ale zachowuj się fair i nie zarzucaj mi, że piszę niemerytoryczne głupoty w sytuacji, gdy tak ne jest.
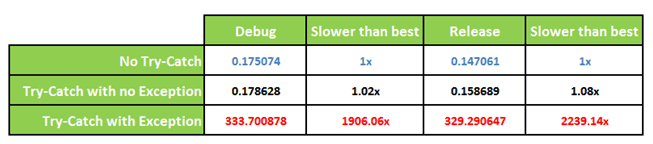
Zgadzam się, że zazwyczaj stosowanie wyjątków aplikacji nie wywali na plecy ze względów wydajnościowych, co nie zmienia faktu, że są one znacząco wolniejsze niż inne mechanizmy języka.
5
Coś co odróżnia wyjątki od zwykłej instrukcji sterującej, za Jerzym Gręboszem:
w przypadku zwykłego return powrót z funkcji następuje do miejsca jej wywołania
w przypadku wyjątku wracamy gdzie indziej, być może parę poziomów w górę
9
Mała rzecz na którą nikt chyba jeszcze nie zwrócił jeszcze uwagi. Praca na kolekcjach i wyjątki.
Dostaję listę nazw plików i chce je otworzyć, wczytać i sparsować. Gdy mamy api zwracające Either<Error, Result> lub chociaż Try<Result> kod może wyglądać tak:
List<Either<Error,Result>> parsed = filePaths.map(path -> path.open().flatMap(file -> file.readAllLines()).flatMap(text -> parse(text)));
Dla API rzucających wyjątki nie zapiszemy tego tak prosto bo wyjątek przerywa aktualną pracę.
O ile wyjątki jeszcze bronią się przy pojedynczych wartościach, to przy przetwarzaniu kolekcji jest to tragedia. Potem mamy walidacje na formularzach które wykrywają pierwszy błąd zamiast zwrócić wszystkie błędy na raz :(
0
Dla API rzucających wyjątki nie zapiszemy tego tak prosto bo wyjątek przerywa aktualną pracę.
no i gites, no bo jak to sobie wyobrażasz - dostajesz 10 plików do zaimportowania, wywala się jeden, ale ty i tak lecisz dalej?
super integralność danych :P
0
no i gites, no bo jak to sobie wyobrażasz - dostajesz 10 plików do zaimportowania, wywala się jeden, ale ty i tak lecisz dalej?
a jak ma wywalić się n? Będziesz odpalał n razy?
2
WeiXiao napisał(a):
Dla API rzucających wyjątki nie zapiszemy tego tak prosto bo wyjątek przerywa aktualną pracę.
no i gites, no bo jak to sobie wyobrażasz - dostajesz 10 plików do zaimportowania, wywala się jeden, ale ty i tak lecisz dalej?
super integralność danych :P
Jeśli to są np osobne kraje to żaden problem. W jednym systemie przez tydzień nie umieli zaimportować jednego kraju, ale wszystkie pozostałe kraje działały. Całkowicie rozdzielne dane
0
cerrato napisał(a):
- Rzucanie wyjątków jako takie powinno być stosowane w sytuacjach awaryjnych.
- Rzucanie wyjątków mogę zrozumieć jako formę odpowiedzi w przypadku wywołania czegoś zewnętrznego - gdy ta funkcja/biblioteka napotka problem i chce zwrócić informację do podmiotu wywołującego, że nie udało się wykonać zadania, ALE
- Takie przekazanie informacji zwrotnej można osiągnąć na inne sposoby - były wymieniane w tym wątku (chociażby jakiś kod błędu, klasa opakowująca error, mechanizmy typowe dla niektórych języków typu either itp.)
- NIE PODOBA MI SIĘ
exception driven development- czyli w przypadku dawanego jako przykład konwertera ścieżka w stylu "daję coś do convertera, on jeśli zwróci wyjątek to przekazuję do innego convertera, jeśli on zwróci wyjątek to do kolejnego itp.".- Poszerzając poprzedni punkt - od tego jest logika aplikacji, żeby sprawdzić, czy dane są odpowiedniego typu, albo przy dzieleniu czy dzielnik jest różny od zera. Dopiero jeśli jestem przekonany, że dane są OK, to je pcham dalej
- Kontynuując pkt. 5 - jeśli konwerter dostanie dane nieodpowiednie to może rzucić wyjątek (albo zgodnie z pkt. 3 - przekazać informację zwrotną w inny sposób) ALE to nie jest element zwykłego wykonania programu, tylko sytuacja naprawdę awaryjna - czyli taka, w której mimo zachowania ostrożności, coś poszło niezgodnie z założeniami
Noo, nie wiem co mamy z tym zrobić. Przedstawiłeś po prostu 6 swoich opinii, ale nie widzę tutaj żadnych argumentów (tylko opinie właśnie) i nie widzę też pytań, więc nie rozumiem jak się mam odnieść do tego?
PS, dodam jeszcze że średnio że przeinaczasz moje słowa.
czyli w przypadku dawanego jako przykład konwertera ścieżka w stylu "daję coś do convertera, on jeśli zwróci wyjątek to przekazuję do innego convertera, jeśli on zwróci wyjątek to do kolejnego itp.".
Bo ja nigdzie nie mówiłem o przekazywaniu czegokolwiek "z covertera do kolejnego i kolejnego", tak jak to przedstawiłeś.
Łamie warstwy abstrakcji, łamie hermetyzację, sprawia że więcej niż jeden obiekt wie o PDF'ach
Nie zgadzam się.
Tak naprawdę to ja (jako obiekt wywołujący) nie muszę znać wewnętrznego mechanizmu działania obiektu/funkcji/biblioteki, którą wywołuję. Zamiast odpalićconverter.isPDFValid()(co po części może się zgadzać z tym, co napisałeś - jest zaglądaniem we wnętrzności konwertera, chociaż na bardzo wysokim poziomie abstrakcji, nie mam dostępu do samego PDF, a jedynie odpytuję, czy jest on OK) można daćconverter.isReadyToProccess()i wtedy w zależności od odpowiedzi - albo każę uruchomić konwersję, albo odpalam inną procedurę. Czyli - jeśli załadowałem jakiś plik do konwertera, a mimo tego konwerter mi mówi, że nie jest gotowy do działania, oznacza to, że tego pliku nie da się w ten sposób przetworzyć.
Łamie, i to z conamniej dwóch powodów jakie mi przychodzą na myśl.
Po pierwsze, to że cała logika jest schowana w isPDFValid() to nie znaczy że nie złamałeś poziomów abstrakcji, bo nadal Twoja warstwa oprócz biznesowego case'a że coś jest albo nie jest *.pdfem (który musi znać, bo taka jest jej logika; i wydaje mi się że to masz na myśli), to oprócz tego jeszcze wie że istnieje coś takiego jak poprawny pdf i nie poprawny pdf (i tego już nie powinna). To już nie jest jej odpowiedzialność, i dlatego łamię poziomy abstrakcji. Pamiętaj że w naszym przykładzie logika biznesowa brzmi: "Jeśli ktoś da plik pdf, to go skonwertuj, jeśli nie, to zwróć to co ktoś dostał". Zauważ że w takiej logice biznesowej o której gadamy od początku nie ma słowa o niepoprawnym pdf'ie. To nie zostało uwzględnione, więc proszę, nie dokładaj tego teraz. Jeśli chcesz, to możemy zmienić nasz scenariusz, i dodać do niego gałąż co zrobić jeśli ktoś wrzuci malformed pdf', ale wtedy pozwól mi dobrać inny przykład, odpowiedni do tej logiki. Bo do tej która była w temacie od początku; to Twój przykład złamał poziom abstrakcji, przez to że wiedział o tym że istnieje coś takiego jak niepoprawny pdf.
Po drugie, w naszym przykładzie jest to hiper proste, uproszczone do granic, ponieważ są tylko dwa przypadki "jest Pdf"/"nie jest pdf". Ale w prawdziwym życiu, po pierwsze case wystąpienia błędu może być dużo bardziej skomplikowany niż boolean (niż zwykłe true lub false), więc nie wystarczy if; a po drugie tych case'ów może być wiele, więc musiałoby być kilka ifów żeby to ogarnąć; co z kolei znowu złamie poziomy abstrakcji a tym razem także SRP.
Jest to sytuacja, w której w normalnej logice sprawdziłem, że plik został dostarczony, wydawało się że jest poprawny, ale podczas jego przetwarzania coś się wykrzaczyło.
Zmieniasz nasz scenariusz, w początkowej historyjce nie było nic mowy o niepoprawnym pdf'ie. Jeśli chcesz uwzględnić taką gałąź to możęmy się umówić na inną, ale pozwól mi dobrać inny przykład, odpowiedniejszy. Bo teraz zmieniłeś scenariusz, dopasowujesz mój przykład który był przeznaczony do poprzedniego, i krytykujesz wynik. Umówmy się na jeden schema / jedna user story / jedną logikę biznesową, i mówmy o wyjątkach przez jej kontekst.
Dobrze, dopasujmy ścieżkę, do Twojego, który właśnie wymyśliłeś. Czyli porzucamy scenariusz: "Jeśli użytkownik wyślę pdf, to skonwertuj na html' jeśli wyśle html to go prześlij dalej". Porzucamy go całkowicie.
Bazujmy na Twoim scenariuszu.
Storka biznesowa:
Jeśli użytkownik wyśle poprawnego pdf'a, to skonwertuj go na html'a.
Jeśli użytkownik wyśle niepoprawnego pdf'a, to odpisz mu: "niepoprawny pdf"
Jeśli użytkownik wyśle inny plik, to zwróć go normalnie.
Tak, rozumiem że to jest Twój zmieniony scenariusz. Więc żebyśmy mieli jasnośc, przedstawię pseudo-kod jak ja bym to ogarnął
class UserController {
function upload(File $file) {
try {
pdfConverter.convert(file);
} catch (NotPdfException exception) {
return file;
}
catch (MalformedPdfException exception) {
return response(400, "Malformed pdf uploaded");
}
}
}
Jeśli chcesz wskazać jakieś wady w tym podejściu, to proszę :> Ale nie zmieniaj scenariusza, i nie dodawaj kolejnych aspektów, a jeśli chcesz zmienić scenariusz to proszę poinformuj mnie, żebym mógł podać kod którym bym to opendzlował.
To jak z porzadkami w domu - możesz mieć syf w salonie, ale posprzątanie jedynie parapetu i szafki już trochę ten bałagan zmniejszy ;)
Nie rozumiem w jaki sposób sprzątanie domu ma się do programowania. Nie adekwatne porównanie moim zdaniem.
A co do tego, że są to uwagi niemerytoryczne - nie zgodzę się. OK, ja nie jestem jakimś autorytetem, ale zobacz co pisali inni, chociażby:
@jarekr000000 - Rzucanie wyjątkami a "zwykłe" zaprojektowanie obsługi błędu
@somekind - Rzucanie wyjątkami a "zwykłe" zaprojektowanie obsługi błędu
@MarekR22 - wyjątki kompletnie bez sensu -C++ i obsługa wyjątków jest ~40 razy wolniejsza od standardowego zwijania stosu [...] koszt zwijania stosu podczas wyjątków jest absurdalny, dlatego ograniczyłbym ich użycie do sytuacji literalnie wyjątkowych
@nalik - wyjątki kompletnie bez sensuPoza tym parę linków spoza 4P:
https://theburningmonk.com/2011/09/the-cost-of-throwing-exceptions/
https://php.watch/articles/php-exception-performance
Throughout all PHP versions tested, the try/catch blocks themselves have relatively small performance impact. However, throwing an Exception, which requires PHP to collect the stack trace and create an Exception object can be costly, and is up to 9 times slow.
Generally, the use of exceptions for control flow is an anti-pattern [...] Exceptions are, in essence, sophisticated GOTO statements
No, ale nie ma tu podanych twardych danych nigdzie. Rozumiem, że coś może być 40, 50 albo i nawet 100x wolniejsze, ale bez profilera te dane o niczym nie świadczą. Jeśli wykonanie ifa trwa 5 nanosekund, a wyjątek trwa 50xdłużej, czyli 250 nanosekund; to to i tak jest duuużo zbyt mało żeby mówić o choćby nawet nikłej optymalizacji.
Przypomnę 3 zasady optymalizacji.
- Don't.
- If you think you should, don't.
- If you do, use profiler.
Rozumiem, że możemy mieć inne podejście, możesz nie zgadzać się z tym, co napisałem (albo do mnie może nie trafiać Twoja argumentacja), ale zachowuj się fair i nie zarzucaj mi, że piszę niemerytoryczne głupoty w sytuacji, gdy tak ne jest.
Nie zarzucaj, że ja zarzucam że piszesz "głupoty". Specjalnie nie używam takich określeń jak "głupota", bo nie chcę być tak odebrany.
Po drugie, nie mówiłem że piszesz zawsze niemerytorycznie, tylko że użyłeś niemerytorycznego zagrania w jednym miejscu i nawet podałem Ci miejsce gdzie je wyłapałem. I tym miejscem było:
"machina wyjątków" oraz "jeden prosty if"
Tylko je uważam za niemerytoryczne. Do pozostałych cześci posta nie mam zastrzerzeń.
jeśli konwerter dostanie dane nieodpowiednie to może rzucić wyjątek (albo zgodnie z pkt. 3 - przekazać informację zwrotną w inny sposób) ALE to nie jest element zwykłego wykonania programu, tylko sytuacja naprawdę awaryjna - czyli taka, w której mimo zachowania ostrożności, coś poszło niezgodnie z założeniami
Tylko że, słowo "awaryjna" to nie jest dobrze zdefiniowane słowo w nomeklaturze programistycznej nie uważasz? Gdzie 5 programistów, tam 5 interpretacji tego co jest awarią, a co nie jest. Pomnóż to jeszcze przez ilość warstw w aplikacji.
@cerrato PS: Nie odniosłeś się wgl do argumentu, że jeśli napiszę unit test UserControllerTest, który sprawdza czy dla *.pdf i dla *.html przechodzą poprawne ścieżki, to taki unit nie będzie w stanie wykryć czy to jest wyjątek czy if, i nawet nie powinien być w stanie. Ergo, to jest szczegół implementacyjny.
4
@TomRiddle: Myślę, że to jest moment, w którym powinniśmy sobie obaj dać spokój. Bo chyba już każdy z nas powiedział co miał do powiedzenia i zaczynają się przepychanki w stylu "ja tego nie napisałem" albo "nie odniosłeś się do tamtego".
Ja w odpowiedz na Nie odniosłeś się wgl do argumentu, że jeśli napiszę unit test UserControllerTest mogę napisać, że tak samo Ty, pisząc Po pierwsze, to że cała logika jest schowana w isPDFValid() nie ustosunkowałeś się do tego, co napisałem - że możemy zamienić isPdfValid na converter.isReadyToProccess() i wtedy już zarzut o łamaniu hermetyzacji czy innych SOLID'ów by był mocno osłabiony.
Tak samo z tym porządkowaniem mieszkania - nie wierzę, że nie zrozumiałeś co chciałem przekazać przez tą analogię, ale na wszelki wypadek napisze jaśniej - nawet jeśli są inne rzeczy, które można ogarnąć, albo które stwarzają problemy, to nie znaczy, że to usprawiedliwia dokładanie kolejnych.
We wcześniejszym poście napisałeś Proponuję streścić niejasności, może napisz statementy, więc zgodnie z Twoją prośbą postarałem się jeszcze raz, skrótowo i maksymalnie zwięźle przedstawić moje podejście do tematu, a w odpowiedzi dostałem Noo, nie wiem co mamy z tym zrobić. Przedstawiłeś po prostu 6 swoich opinii, ale nie widzę tutaj żadnych argumentów (tylko opinie właśnie) i nie widzę też pytań, więc nie rozumiem jak się mam odnieść do tego?. Dla mnie sytuacja jest jasna - przedstawiłem swoją opinię (która w trakcie wcześniejszy postów i dywagacji mogła się rozmyć) i myślałem, że się do niej ustosunkujesz.
W każdym razie - teraz przeszliśmy na walkę kto kogo przegada, wytknie błąd w wypowiedzi, złapie za słówko albo znajdzie rozjazd w logice. A to nie o to chodziło. Bardzo Ci dziękuję (i piszę to całkowicie serio - bez szydery czy złośliwości) za to wszystko co pisałeś, widzę że włożyłeś w to dużo energii, ale jak dla mnie to już wystarczy, jakoś nie widzę szans, żebyśmy (albo w sumie - żebym ja, nie chcę pisać w Twoim imieniu) napisali jeszcze coś sensownego.
4
TomRiddle napisał(a):
To zależy od prezentacji tych logów w narzędziu do monitoringu które wybrałeś. Jeśli korzystasz ze splunka albo czegoś podobnego to możesz je pogrupować, tak że nawet jeśli wyjątek
NotSoImportantExceptionpoleci 1000x to zobaczysz go i tak, zgrupowanego w zakresie którym wybrałeś.
Tak, mogę sobie filtrować logi. Ale mogę też nie nadużywać wyjątków, i nie musieć później filtrować nieistotnych rzeczy. Ta druga opcja wydaje mi się znacznie bardziej logiczna, bo nie dokładam sobie roboty.
Ciekawiej się robi, jeśli system monitorujący podnosi alarm i np. budzi ludzi w środku nocy, gdy wystąpią jakieś anomalie, typu więcej niż 1 exception na minutę. Wtedy koszt rzucenia wyjątku bez powodu rośnie drastycznie. Oprócz wkurzenia kolegów z pracy - to jest bezcenne. ;)
Także argument z "gąszczem" i "umykaniem" do mnie nie trafia, bo to kwestia umiejętności korzystania z narzędzi diagnostycznych.
To nie kwestia umiejętności lecz czasu.
No zgadzam się. Ale czemu nie wyjątkiem, tylko return-typem?
Bo typ zwracany widać, a wyjątku nie. To, jakie możliwe błędy mogą zostać zwrócone widzę w deklaracji funkcji, więc mogę każdy z nich oddzielnie obsłużyć. W przypadku wyjątków nie mam tego komfortu, mogę jedynie zgadywać jaki wyjątek zostanie rzucony w danej sytuacji i spróbować go obsłużyć. W efekcie połowę mogę obsłużyć niepotrzebnie (bo nigdy nie jest zwracana), a tej potrzebnej mi połowy nie obsłużę (bo autor rzuca inne wyjątki niż bym zakładał).
Innymi słowy; co za różnica jakiego elementu języka użyjesz, skoro zachowanie będzie takie samo. Trochę jak podobne użycie
ifiswitch.
Nie, nie będzie takie samo. Aplikacja niedziałająca dla wszystkich użytkowników, a jedna funkcja niedziałająca dla jednej osoby, która jej prawdopodobnie źle używa, to są skrajnie różne rzeczy.
Im dłużej czytam Twoje wypowiedzi, tym coraz większe wrażenie mam, że kiedy wypowiadasz się użyciu tych wyjątków, to mówisz tylko o aplikacjach end-userów, które są bardzo wysokopoziomowe, korzystają z wysokopoziomowych frameworków, i mają dosyć mało logiki ale dużo scenariuszy biznesowych (jak np panele administracyjne jakichś serwisów). Czy to dobre wrażenie?
W pewnym sensie tak... mam na myśli pracujące cały czas systemy, które co jakiś czas przetwarzają jakieś dane otrzymane z zewnątrz (czy od userów czy nie, to nie ma znaczenia dla tego tematu). Ilość logiki czy scenariuszy biznesowych nie ma znaczenia dla architektury. Aplikacja "dla userów" od takiej "nie dla userów" jak dla mnie różni się tylko ilością walidacji na wejściu.
Nie chcesz wiedzieć o sfailowanych encodingach, więc nie chcesz ich logować, ale narzędzia z których korzystasz traktują wyjątki jak błędy i je logują; więc nie rzucasz wyjątków, więc musiałeś znależć inny sposób propagacji błędnych wartości więc przekazujesz
PageResult. Domyślam się że taki kompromis jest dla Ciebie akceptowalny
No, tylko ja dużo wcześniej zacząłem zwracać wyniki niż używać jakichś zaawansowanych systemów diagnostyki w systemach mikroserwisowych. I nie uważam, aby było w tym cokolwiek kompromisowego. Kompromis to coś, na czym się w chociaż jednym aspekcie cokolwiek traci. Nie rzucając wyjątków niczego nie tracę.
Szczerze mówiąc, nie sądzę że takie podejście sprawdzi się w tych przypadkach, wydaje mi się że wyjątki i ich elastyczność sprawdzą się dużo lepiej.
Aplikacja desktopowa czy moblina też jest blisko usera.
A biblioteka, tool, dllka, moduł, framework - one wszystkie też mają zwrócić błąd w rozsądny sposób, w końcu zazwyczaj są one po pierwsze są wykorzystywane w aplikacjach/systemach dla końcowych użytkowników, a po drugie można potraktować programistę z nich korzystającego jako użytkownika.
Kompilator - w jakiej sytuacji ma rzucać wyjątek? Niemożliwości skompilowania kodu?
Sterownik - no tu zazwyczaj jeśli coś jest nie tak, to jest to sytuacja krytyczna.
Uczenie AI - czym to się różni pod względem obsługi błędów od programu dla użytkownika? Coś się nie uda, więc o czymś trzeba poinformować.
Nie widzę w Twoich wypowiedziach zupełnie miejsca na wyjątki które nie są do ohandlowania, a to jest dokładnie to o czym mówię od 5 odpowiedzi.
Ale co to znaczy wyjątek nie do ohandlowania?
Przykładem tego o czym jak mówię, jest np taki kod
new String("\xc3\x28", "UTF-8")("\xc3\x28"to jest niepoprawny unicode). Ja sobie nie wyobrażam żeby taki kod skończył się czymkolwiek innym niż wyjątkiem. Correct me if I'm wrong?
Ten kod jest dziwny, ale z uwagi na to, że to konstruktor jakiegoś niskopoziomowego typu, to raczej nie ma innego wyjścia niż wyjątek.
Zróbmy eksperyment, może nie mam racji zupełnie. Powiedzmy, że mamy funkcje która ma dostać listę stringów, i ma z nich skleić ścieżkę. Np z
join("folder/", "/b/", "c", "", "d"). Jakbyś zaprojektował taką funkcje, jakie miałaby return type'y, czy rzucałaby kiedykolwiek jakikolwiek exception, i jakie case'y byś przewidział? Zakładamy że Ty ją musisz napisać i nie jest dostarczona przez framework.
No dla tak przedstawionych wymagań, to moja implementacja takiej funkcji zawsze zwróci stringa i nigdy nie rzuci wyjątku. :)
Dodatkowo, dodatkowo. Jak głęboko takie
PageResultmogą sięgnąć? Czy to znaczy że idealnie napisana aplikacja nie ma return type'ów takich jakintlubString, to każda funkcja zwracaPageResultktóry zawiera albo wynik albo każdy błąd z klasy?
Każda publiczna metoda klasy, bo jakieś prywatne metody w klasach, to mogą zwracać różne rzeczy.
cerrato napisał(a):
@somekind: a w jaki sposób Ty byś chciał zwrócić tą informację? @TomRiddle chwilę wcześniej napisał (Rzucanie wyjątkami a "zwykłe" zaprojektowanie obsługi błędu) że takie zwracanie błędu jest niefajne i (szczerze mówiąc) ma w tym dużo racji. I z jednej strony rozumiem i się zgadzam z tym, co On napisał, ale z drugiej to nie czaję/nie przemawia do mnie sterowanie przebiegiem programu w oparciu o wyjątki (poza sytuacjami naprawdę awaryjnymi).
Czyli mamy 3 opcje: jakaś klasę/obiekt, w której będą zaszyte informacje o błędzie, magic value oraz wyjątek. Czy masz pomysł na coś innego? Przypominam, że ten wątek jest raczej taki ogólny, więc nie idźmy w kierunku rozwiązań typowych jedynie dla niektórych języków.
No coś w tym stylu: klasa Result<T> z polami T Value i ErrorBase Error, a z ErrorBase mogą już dziedziczyć konkretne klasy opisujące konkretne problemy. Tylko oczywiście też bez przesady z głębokością tej hierarchii. Jedyne wymaganie to język (obiektowy) obsługujący typy generyczne.
TomRiddle napisał(a):
Myślisz o całej tej sytuacji z globalnego punktu widzenia, z punktu widzenia usera. Tak, plik tak czy tak ma być obsłużony; więc userowi żaden błąd i żaden wyjątek się nie pokaże. Dla użytkownika aplikacji to nie jest sytuacja wyjątkowa. Ale klasa
PdfToHtmlConverterspodziewa się PDF'a. Nie powinna dostać htmla, a jeśli go dostanie powinna rzucić wyjątek. Klasy niższe nie powinny polegać na założeniach klas wyżej. Wyobraź sobie pięć aplikacji. Nazwijmy ją Apple, Orange, Pear, Cherry i Banana.
- Aplikacja Apple działa tak jak opisaliśmy, jeśli dostanie pdf'a to konwertuje go na html'a, a jeśli coś innego, po prostu go zwraca.
- Aplikacja Orange działa tak, ze jak dostanie pdf'a to go konwertuje na html'a, a jak dostanie coś innego, np html'a właśnie, to go wsadza w iframe'a i dopiero potem wsadza w html'a
- Aplikacja Pear działa tak, że jak dostanie pdf'a to go konwertuje na html'a, a jak dostanie coś innego, to robi screenshota i tego screenshota wkłada w html'a
- Aplikacja Cherry to mikroserwis który może dostać tylko pdf'a i nie może dostać nigdy html'a, jeśli dostanie to odpowiada statusem 400 bad request.
- Aplikacja Banana crawluje internet w poszukiwaniu pdf'ów, znajduje pliki które faktycznie są pdf'em i zamienia je na HTML przy pomocy
PdfToHtmlConverter.Moim zdaniem, klasa
PdfToHtmlConverterw każdej z tych aplikacji powinna wyglądać dokładnie tak samo.
Jak najbardziej!
Tzn, gdyby faktycznie te aplikacje istniały, to klasę
PdfToHtmlConvertermożna by wynieść do bibliotekifruit-commonsi jej użyć tak samo w każdej z nich. Pytanie pada, jak jej użyć tak samo, skoro każda aplikacja wymaga innej reakcji na użycie pliku który nie jest pdf'em?
A co bibliotekę interesuje, jak aplikacja będzie jej używać? To jak obsłużyć błąd, to decyzja aplikacji, a nie biblioteki.
Jedyny sensowny sposób to jest taki, że klasa rzuca wyjątek, który mówi: "Jestem PDF' konwerterem a nie dostałem PDF'a", i dopiero warstwa wyżej która użyła tej klasy wie co wtedy zrobić. Bo to aplikacja ma decydować co zrobić z nie-pdf'em, a nie klasa która ma go skonwertować.
A w jaki sposób zwrócenie wyniku zamiast wyjątku przeszkadza aplikacji?
Czyli przemilczeć buga? No nie wiem czy to taki dobry pomysł. Języki programowania to narzędzia, mają być reliable. Jeśli ja ich źle używam (bo np przekazuje html'a do pdf konwertera) to chcę żeby ta klasa mi o tym powiedziała. Nie chcę, żeby zakładała że nie-pdf' może się tam znaleźć.
Jeśli jawnie rzucasz wyjątek NotPdfException, to i tak to zakładasz. Tylko używasz niekoniecznie optymalnego mechanizmu do poinformowania o tym.
Żeby zrobić
ifa, zanim się da plik doPdfConverter.convert(file), to trzeba zawołać coś takiegoif (file.isPdf())prawda? No albo ewentualnieif (file.getName().endsWith(".pdf"))czy coś podobnego. I teraz, co to znaczy. To znaczy, że klasa wyżej, ponadPdfConverterumie rozpoznać czy coś jest plikiem pdf czy nie. To prawda, możesz to wydelegować do utilsa,if (FileUtils.isPdf(file)), ale to ciągle oznacza, żę klasa która wołaPdfConvertermusi wiedzieć o tym czy plik jest pdf'em czy nie, albo bezpośrednio, albo pośrednio przez ten util. Więc złamała poziomy abstrakcji. Moim zdaniem, tylkoPdfConverter.convert(), albo jego klasy niżej, powinny wiedzieć co jest pdf'em a co nie.
No czyli przy Twoim podejściu (czyli wrzucamy bez sprawdzenia i czekamy na sukces albo wyjątek) zamiast domyślnym (najpierw sprawdzamy, potem przetwarzamy), aplikacja Bananas będzie próbowała wepchnąć do PdfConvertera wszystkie pliki z internetu? Jesteś pewien, że to dobry pomysł?
Bo jak dla mnie to tego typu sposób programowania jest jeszcze gorszym pomysłem niż pierwotny problem rozważany w tym wątku. Bo o ile nadmiar wyjątków jest do przeżycia i obejścia, to tutaj jest mowa o jakiejś architekturze brute-force. Po co coś sprawdzać czy jest woda w basenie, po skoku przecież i tak się tego dowiemy.
Każda z Twoich aplikacji oprócz Cherry powinna umieć rozpoznać, czy plik jest PDFem czy nie, aby nie próbować robić rzeczy bezsensownych.
PdfConverter oczywiście też musi to umieć, aby móc zwrócić błąd.
Robisz walidację wejścia w swoich aplikacjach, czy próbujesz zapisać błędne wartości w bazie i liczysz na naruszenie constraintów?
0
Dla pogubionych Pythonowych dusz tylko dorzucę, że ta dyskusja nie dotyczy Pythona