Cześć, zastanawia mnie porównanie zliczania referencji stosowanego np. w C++ oraz Mark and Sweep stosowanego w JVM. Teoretycznie wydaje się że zliczanie referencji jest efektywniejsze, bowiem nie ma pauz na GC - koszt zwalniania zaalokowanego miejsca jest bardziej rozłożony w czasie i równomierny. Z drugiej strony wadą jest słabe radzenie sobie z cyklicznymi referencjami, z czym akurat sobie umie w miare dobrze popradzić M&S. Czy to że M&S jest tak popularny wynika z tego że łatwiej sobie poradzić z cyklicznymi referencjami? A może performance M&S nie jest taki słaby? Haskell stosuje Garbage Collector a nie zliczanie referencji, mimo że raczej tam nie ma cyklicznych zależności.
@Shalom @mar-ek1 @jarekr000000
0
0
Nie rozumiem. Przecież jak masz cykliczne referencje, to zliczanie z definicji odpada. Druga sprawa - dlaczego twierdzisz, że zliczanie referencji implikuje brak pauz GC?
0
Zliczanie referencji nie rozwiąże cykli, a przynajmniej nie w naiwnym podejściu.
Jest masa publikacji naukowych odnośnie wydajności zliczania referencji i zazwyczaj jest to wolniejsze. Poszukaj i poczytaj.
6
CMS (Concurrent Mark and Sweep) został oznaczony jako przestarzały w Javie 9 ( https://openjdk.java.net/jeps/291 ), a w Javie 14 został usunięty ( https://openjdk.java.net/jeps/363 ). G1 GC w najnowszych wersjach Javy jest na tyle dopracowany, że może zastąpić z powodzeniem CMSa.
Zliczanie referencji w C++ w środowisku wielowątkowym jest kosztowne, a obecnie nawet dość błędogenne. W C++20 mają dość atomic referencje, które będą bardziej solidne: https://www.modernescpp.com/index.php/atomic-smart-pointers
Źle zrobiony destruktor może wysadzić stos jeśli źle ustawisz zależności destruktorów: https://softwareengineering.stackexchange.com/questions/271216/will-destructing-a-large-list-overflow-my-stack Przy tracing GC to nie występuje, bo tam nie ma tego typu zależności (GC ma swoją kolejkę śmieci i je obrabia jak chce, nie trzeba wywoływać destruktorów/ finalizerów w żadnej specjalnej kolejności). Nawet jeśli stos nie wybuchnie to i tak przy destrukcji dużej struktury danych nastąpi duża pauza, bo destruktory działają synchronicznie. Niskopauzowe GC usuwają obiekty bez zatrzymywania programu (np http://openjdk.java.net/projects/shenandoah http://openjdk.java.net/projects/zgc ).
Niektóre GC są compacting tzn defragmentują pamięć. Jeśli np w danej (np 4-kilobajtowej) stronie pamięci masz zaalokowane 10 bajtów to nie możesz jej np oddać systemowi. Jeśli GC nie przesuwa obiektów ze stron prawie pustych do stron bardziej zapełnionych (to jest to kompaktowanie) to ogólnie tracisz użytkową pamięć. Chyba wszystkie GC Javowe oprócz CMSa są compacting. Firefox też ma compacting GC: https://hacks.mozilla.org/2015/07/compacting-garbage-collection-in-spidermonkey/ Inne przeglądarki czy platformy programistyczne pewnie też.
0
CMS (Concurrent Mark and Sweep) został oznaczony jako przestarzały w Javie 9 ( https://openjdk.java.net/jeps/291 ), a w Javie 14 został usunięty ( https://openjdk.java.net/jeps/363 ). G1 GC w najnowszych wersjach Javy jest na tyle dopracowany, że może zastąpić z powodzeniem CMSa.
@Wibowit może źle się wyraziłem. Nie chodziło mi konkretnie o nazwę GC w Javie tylko o odśmiecanie przez zaznacznie używanych obszarów pamięci(używanie rootów GC) i dealokacje pamieci juz niedostępnej.
Zliczanie referencji w C++ w środowisku wielowątkowym jest kosztowne, a obecnie nawet dość błędogenne.
W sumie to wydaje się bardzo logiczne - problemem jest sensowne współdzielenie referencji przez wątki i aktualizacja licznika.
3
Nie chodziło mi konkretnie o nazwę GC w Javie tylko o odśmiecanie przez zaznacznie używanych obszarów pamięci(używanie rootów GC) i dealokacje pamieci juz niedostępnej.
Tracing GC. Mark and Sweep jest dużo bardziej szczegółowym pojęciem określającym pewien algorytm.
Co do zliczania referencji to raczej nie stosuje się go, jeżeli infrastruktura pozwala na tracing. Największym problem są wspomniane cykle i duży koszt tworzenia, manipulacji licznikiem i niszczenia. W takiej Javie koszt alokacji jest praktycznie zerowy, sama dealokacja też jest darmowa, jeżeli obiekt szybko ginie.
Kiedy zliczanie referencji ma sens:
- nie da się użyć tracingu (C++, Rust). Wysoko wydajnościowy tracing wymaga dużo założeń np. możliwość przeniesienia pamięci, albo określona struktura sterty w celu ułatwienia skanowania. W C++ istnieją algorytmy wykorzystujące tracing np. https://chromium.googlesource.com/chromium/src/+/master/third_party/blink/renderer/platform/heap/BlinkGCAPIReference.md . Inna sprawa, że użycie jest niewygodne i tutaj brak wymaganego runtime sprawia, że zliczanie referencji jest po prostu wygodniejsze
- krótsze pauzy. W dzisiejszych czasach mamy takie algorytmy jak ZGC, ale jakieś 10 lat temu sprawa wyglądała inaczej. Co ciekawe ZGC działa trochę analogicznie jak zliczanie referencji tj. dużo pracy wykonywanej jest w czasie używania danej zmiennej w porównaniu do innych algorytmów, gdzie wszystko dzieje się na boku.
- deterministyczna kolejność niszczenia obiektów, da się bez tego żyć, ale to na pewno jakiś plus
- możliwość dowolnego przedłużenia czasu życia pamięci. Ma to sens, jeżeli nasza aplikacja działa przykładowo w trybie request response. W tym wypadku możemy przedłużyć czas życia jakiegoś dużego obiektu do momentu, kiedy zwróciliśmy już response wykonując dealokację, gdy nikt na nas nie czeka
2
Zliczanie referencji też może skutkować długimi pauzami - czasami usunięcie korzenia jakiegoś grafu wyzwala kaskadowo setki tysięcy małych delete i bywa to odczuwalne. Jest natomiast detetministyczne.
Uzywałem RC w kodzie C++ - koniec lat 90-tych. Era fascynacji programowaniem obiektowym, wzorcami i UMLem. W takim - imperatywnym - kodzie walka z cyklicznymi referencjami nie była jakimś specjalnym, ani uciążliwym wyzwaniem.
Nie wyobrażam sobie natomiast takiej walki we wspołczesnym, choćby lekko funkcyjnym kodzie, ale nie próbowałem - więc może tylko mi się zdaje.
Bardzo jest dla mnie dziwna decyzja o użyciu RC w Swifcie. Najgorsze, że to niestety w środowisku Apple, więc nijak nie ufam opowieściom, że nie stanowi to żadnego problemu - dla fanboyów nawet objective C był zupełnie spoko językiem.
EDIT:
Tu jeszcze taka uwaga, że niemutowalność nie chroni przed cyklami. Łatwo sobie sprawdzisz w Kotlinie.
A tu haskell
data A = A B
data B = B A
c::A
c = A ( B c)
4
W Pro .NET Memory Management, jest wprawdzie krótki, ale teroretyczny rodział o zliczaniu referencji i róznych jego odmianach, strona 42 "Reference Counting", polecam lekturę, a tutaj podsumowanie z tego rodziału:
Advantages
• Deterministic deallocation moment - we know that deallocation will
happen when an object’s reference counter will drop to zero. Therefore,
as long as it is no longer needed, the memory will be reclaimed.
• Less memory constraint - as memory is reclaimed as fast as objects
are no longer used, there is no overhead of memory consumed by the
objects waiting to be collected.
• Can be implemented without any support from the runtime.
Disadvantages:
• Such a naive implementation as at Listing 1-8 introduces very big
overhead on Mutator.
• Multithreading operations on reference counters require well-thought
synchronization, which can introduce additional overhead.
• Without any additional enhancements, circular references cannot be
reclaimed.
3
W takiej Javie koszt alokacji jest praktycznie zerowy
Jako praktyk Javy zostałem wywołany do tablicy... no i nie mogę się z tymi twierdzeniami zgodzić.
Mit "praktycznie zerowego kosztu alokacji" wziął się stąd, że faktycznie SAMA alokacja jest banalnie prosta - "sprawdź, czy jest wystarczająco dużo miejsca i przesuń wskaźnik do przodu". Wygląda to faktycznie nieco taniej niż "znajdź odpowiedni kawałek wolnej pamięci na free-list" i faktycznie w szczególnych przypadkach (zwłaszcza w mikrobenchmarkach) bywa tańsze.
Jednak prawdziwy koszt tworzenia obiektu następuje chwilę później, jest dość nieoczywisty i czasami zaskakująco duży:
-
Alokuje się po to, aby tej pamięci użyć. W przypadku scalających GC, przy alokacji dostajemy zawsze pamięć, która nie była dotykana co najmniej od poprzedniego cyklu sprzątania. Oznacza to, że ta pamięć na pewno nie jest w cache L1, L2, a może nawet w L3. Wskaźnik na nową pamięć dostajemy praktycznie natychmiast, ale robimy pierwszy dostęp do niej i mamy na dzień dobry cache-miss. I tak z kilku cykli CPU robi się co najmniej kilkadziesiąt. Dodatkowo jako bonus - wypychamy inne dane, które były wcześniej z cache.
-
Każda kolejna alokacja przybliża moment, kiedy TLAB się skończy i trzeba będzie zaalokować nowy z globalnej puli. A te w globalnej puli też się skończą i wtedy (w uproszczeniu) włącza sie GC. Im więcej alokujesz, tym częściej działa GC. Koszt GC należy doliczyć do kosztów alokacji.
sama dealokacja też jest darmowa, jeżeli obiekt szybko ginie.
To "jeśli" to w praktyce niestety duży problem. Najlepsza metoda na zabicie GC to zaimplementowanie struktur typu cache - mnóstwo obiektów o średnim i długim czasie życia, ale nie permanentnym.
Co do zliczania referencji, to ono jest drogie jako uniwersalna metoda działająca w runtime, bez wsparcia kompilatora / języka. Natomiast potrafi być zaskakująco tanie, jeśli język wspiera coś takiego jak przesuwanie lub pożyczanie obiektów - w takiej sytuacji po pierwsze prawie nigdy nie potrzebujesz zliczania referencji, a tam gdzie potrzebujesz, aktualizacje liczników referencji mogą być bardzo rzadkie. Aktualizacja licznika to jeden cykl CPU, więc dopóki nie robi się tego tysiącami, to jest niezauważalne.
1
Alokuje się po to, aby tej pamięci użyć. W przypadku scalających GC, przy alokacji dostajemy zawsze pamięć, która nie była dotykana co najmniej od poprzedniego cyklu sprzątania. Oznacza to, że ta pamięć na pewno nie jest w cache L1, L2, a może nawet w L3. Wskaźnik na nową pamięć dostajemy praktycznie natychmiast, ale robimy pierwszy dostęp do niej i mamy na dzień dobry cache-miss. I tak z kilku cykli CPU robi się co najmniej kilkadziesiąt. Dodatkowo jako bonus - wypychamy inne dane, które były wcześniej z cache.
Liniowa alokacja to raczej najprostszy scenariusz dla hardware prefetching znanego od lat 90-tych: https://en.wikipedia.org/wiki/Cache_prefetching
Równie dobrze można powiedzieć, że jeśli często pchasz kopie danych na stos (zamiast wskaźników do nich) i ten tak ci rośnie że sumarycznie stosy zajmują kilka razy więcej pamięci niż cache to ogólnie tracisz na całym procederze. Czy na pewno?
Jeśli w danym momencie używasz dużo małych obiektów rozsianych po stercie to cache (mające pewną ziarnistość znacznie większą niż bajt, np 64 bajty) będzie działało mniej efektywnie niż gdyby te małe obiekty były obok siebie.
Możliwych scenariuszy jest wiele, w każdym przypadku trzeba sobie zrobić rachunek zysków i kosztów.
Aktualizacja licznika to jeden cykl CPU, więc dopóki nie robi się tego tysiącami, to jest niezauważalne.
Jeśli licznik jest atomic to na pewno nie trwa jeden cykl.
1
Krolik napisał(a):
- Alokuje się po to, aby tej pamięci użyć. W przypadku scalających GC, przy alokacji dostajemy zawsze pamięć, która nie była dotykana co najmniej od poprzedniego cyklu sprzątania. Oznacza to, że ta pamięć na pewno nie jest w cache L1, L2, a może nawet w L3. Wskaźnik na nową pamięć dostajemy praktycznie natychmiast, ale robimy pierwszy dostęp do niej i mamy na dzień dobry cache-miss. I tak z kilku cykli CPU robi się co najmniej kilkadziesiąt. Dodatkowo jako bonus - wypychamy inne dane, które były wcześniej z cache.
IMO to mały problem. Jeżeli nasz kod opiera się głównie na alokacjach, czyli programujemy typowo Javowo tworząc co linię nowy obiekt na heapie to czas dostępu do odpowiedniego poziomu cache i tak nie ma większego znaczenia, ponieważ sam koszt alokacji i często związane kopiowanie/zerowanie jest samo w sobie dużym narzutem. Użyte przeze mnie twierdzenie "darmowa" powinno brzmieć raczej: "dużo taniej niż jakakolwiek inna metoda przy zachowaniu tego samego stylu programowania"
Krolik napisał(a):
Co do zliczania referencji, to ono jest drogie jako uniwersalna metoda działająca w runtime, bez wsparcia kompilatora / języka. Natomiast potrafi być zaskakująco tanie, jeśli język wspiera coś takiego jak przesuwanie lub pożyczanie obiektów - w takiej sytuacji po pierwsze prawie nigdy nie potrzebujesz zliczania referencji, a tam gdzie potrzebujesz, aktualizacje liczników referencji mogą być bardzo rzadkie. Aktualizacja licznika to jeden cykl CPU, więc dopóki nie robi się tego tysiącami, to jest niezauważalne.
Analizująć perf raporty programów napisanych w C++ używających mocno zliczania referencji byłem mocno zdziwiony, że sam koszt użycia licznika jest dość mały. Dużo większym problemem jest samo zwalnianie pamięci poprzez komunikację z alokatorem (nawet jak się wybrało jakiś porządny typu jemalloc czy tcmalloc) i przechodzenie przez drzewo obiektów w celu wywołania destruktorów. Oba te problemy nie występują w javowym modelu pamięci.
0
Co do cachy, w Javie (I nie tylko) jest coś takiego jak WeakReference, SoftReference i offheap więc to jest rozwiązanie pewnych problemów o których pisałeś @Krolik
2
Liniowa alokacja to raczej najprostszy scenariusz dla hardware prefetching znanego od lat 90-tych
Prefetching może zmniejszyć opóźnienie, ale nie zmniejsza całkowitej ilości pracy do wykonania.
Poza tym prefetching działa tylko w specyficznych przypadkach jak masz faktycznie uporządkowaną sekwencję dostępów (np. przeglądanie wektora).
W przypadku alokacji wcale tak nie musi być, bo pomiędzy alokacjami możesz mieć mnóstwo innych dostępów i wtedy to już z punktu widzenia procesora nie wygląda na sekwencyjny dostęp, a całkiem przypadkowy.
w Javie (I nie tylko) jest coś takiego jak WeakReference, SoftReference i offheap więc to jest rozwiązanie pewnych problemów o których pisałeś
WeakReference i SoftReference raczej rozwiązują inne problemy niż te, o których pisałem.
Offheap faktycznie umożliwia implementację długożyjących cache poza GC - ale próbowałeś? Ręczne rzeźbienie przetwarzania stringów w C z makrami to chyba mniejszy masochizm niż offheap w Javie. Mamy implementację cache off-heap w swoim produkcie. Debugowanie tego to bardzo fajna zabawa. Polecam.
Dużo większym problemem jest samo zwalnianie pamięci poprzez komunikację z alokatorem (nawet jak się wybrało jakiś porządny typu jemalloc czy tcmalloc) i przechodzenie przez drzewo obiektów w celu wywołania destruktorów. Oba te problemy nie występują w javowym modelu pamięci.
Żeby przejście przez wszystkie destruktory i zwolnienie pamięci zajęło więcej niż przeciętne GC w Javie (nawet takie jak G1), które powiedzmy trwa ok 100 ms, to musiałbyś zwalniać hurtowo miliony obiektów. Poza tym takie zwolnienie i tak nie pauzuje innych wątków - pauzuje jeden wątek, ten zwalniający, natomiast pozostałe np. 47 rdzeni serwera dalej może wykonywać swoją pracę. A nawet w sytuacji gdyby to było problemem - jest banalne wyjście - zwalnianie w tle albo podzielenie zwalniania na paczki. Czyli jeden prosty do rozwiązania i niezbyt poważny problem (dealokacja) C++ został zastąpiony przez Javę innym, znacznie znacznie poważniejszym i znacznie trudniejszym do rozwiązania (pauzy GC).
Jeśli licznik jest atomic to na pewno nie trwa jeden cykl.
Po pierwsze: A dlaczego miałby być atomic? Przy odpowiednim wsparciu kompilatora wiadomo, które liczniki nigdy nie wyłażą poza jeden wątek, więc te liczniki nie muszą być atomic. W C++ shared_ptr jest atomic, ale już np. w Rust są dwa rodzaje liczników. Atomowy licznik potrzebujesz tylko jeśli zwalniasz obiekt w innym wątku niż go utworzyłeś.
Po drugie: jeden cykl to może nie, ale w optymistycznym przypadku LOCK ADD zajmuje mniej niż 10 cykli (dokładnie 8 uops na Coffee Lake) , a w tym czasie CPU może robić wiele innych rzeczy.
0
Offheap faktycznie umożliwia implementację >długożyjących cache poza GC - ale próbowałeś?
A to nie są jakieś gotowe biblioteki od tego? Zresztą, słyszałem że ponoć GC potrafi się dostosować więc można też użyć innej instancji JVMa do trzymania cachy.
A co do wspieranych przez kompilator liczników referencji, jestem ciekaw czemu ich nie ma w C++ (chyba że sie mylę)
1
Atomowy licznik potrzebujesz tylko jeśli zwalniasz obiekt w innym wątku niż go utworzyłeś.
Raczej jak używam (nie tylko alokuję i dealokuję obiekt, ale też np klonuję wskaźnik) w więcej niż jednym wątku naraz, bo bez atomica licznik się rozjedzie. Oczywiście można kombinować z konwertowaniem między wskaźnikami zliczanymi i nie, ale to chyba sztuka dla sztuki.
Znalazłem benchmark dotyczący alokacji + prefetchingu w Javie: https://www.opsian.com/blog/jvms-allocateprefetch-options/
Nawet w tak patologicznym przypadku jak sama alokacja obiektów prefetching daje zaledwie dwadzieścia kilka % zysku. Gdyby dorzucić logikę biznesową to pewnie różnica znacznie by się zmniejszyła:
Putting the results in context
It’s worth interpreting these benchmarks and their results. For starters, these are microbenchmarks - they are testing one specific operation and it’s highly unlikely you will see a performance impact of the magnitude these tests show. To put some of the allocation numbers in context the CacheSizedObjmicrobenchmark with allocation prefetching enabled is allocating 8.5 gigabytes a second and essentially nothing else. That it is bottlenecked by the store buffer is unsurprising given that stores are all it’s doing. In a bigger application there’s a good chance that some operations will actually be performed on the allocated objects, so giving more time for the store buffer to drain.
Co do:
Po drugie: jeden cykl to może nie, ale w optymistycznym przypadku LOCK ADD zajmuje mniej niż 10 cykli (dokładnie 8 uops na Coffee Lake) , a w tym czasie CPU może robić wiele innych rzeczy.
To chyba jednak nie. Na https://stackoverflow.com/a/39396999 jest napisane:
Note that the lock prefix also turns an instruction into a full memory barrier (like MFENCE), stopping all run-time reordering and thus giving sequential consistency.
Hmm, full memory barrier? Samo LFENCE może już zabić wydajność: https://www.phoronix.com/scan.php?page=article&item=lvi-attack-perf&num=1
Obstawiam, że optymalizacje kompilatora (czyli redukowanie zmian atomowego licznika za wszelką cenę) są kluczowe do utrzymania sensownej wydajności. Pytanie tylko ile jest przypadków w których zawodzą?
Najlepsza metoda na zabicie GC to zaimplementowanie struktur typu cache - mnóstwo obiektów o średnim i długim czasie życia, ale nie permanentnym.
Na pewno? Card tables w generacyjnych GC powinny rozwiązywać ten problem do pewnego stopnia: https://stackoverflow.com/questions/19154607/how-actually-card-table-and-writer-barrier-works
Jeśli odśmiecanie nowych regionów wystarcza (w sensie zwalnia wystarczającą ilość pamięci) to starych nie trzeba w ogóle wczytywać podczas cyklu GC.
2
Raczej jak używam (nie tylko alokuję i dealokuję obiekt, ale też np klonuję wskaźnik) w więcej niż jednym wątku naraz, bo bez atomica licznik się rozjedzie. Oczywiście można kombinować z konwertowaniem między wskaźnikami zliczanymi i nie, ale to chyba sztuka dla sztuki.
W większości przypadków możesz pożyczyć albo przesunąć wskaźnik bez zmiany liczby referencji.
Pożyczenie wskaźnika (przekazanie przez referencję) nie modyfikuje liczby referencji.
Przekazanie wskaźnika do nowego właściciela (np. do funkcji) i wyrzucenie oryginału też nie zmienia liczby referencji.
Klonowanie jest potrzebne tylko jak zmienia się liczba właścicieli danych - tzn. pojawia się nowy właściciel danych wskazywanych przez wskaźnik, ale w praktyce to dość rzadkie sytuacje. Zwykle koszt utworzenia tego nowego właściciela (alokacja) jest większy niż skopiowanie wskaźnika.
Samo LFENCE może już zabić wydajność
Między "może" a "musi" jest duża różnica. Akurat LFENCE i SFENCE na x86 to praktycznie noop, bo wszystkie dostępy są i tak koherentne i uporządkowane. Koszt występuje gdy linia cache jest faktycznie współdzielona między rdzeniami (i do tego nie musisz mieć wcale bariery - przy zwykłych aktualizacjach współdzielonego licznika też będziesz mieć duże opóźnienie). Koszt jest oczywiście niezerowy, bo atomic wyłącza pewne optymalizacje komplatora (np. out-of--order) i wymusza przesłania (nie można tak sobie licznika w rejestrze trzymać), ale dopóki dwa wątki nie zabijają się o wspólny licznik i nie robią milionów aktualizacji na sekundę, nie zauważysz narzutu.
0
W większości przypadków możesz pożyczyć albo przesunąć wskaźnik bez zmiany liczby referencji.
Pożyczenie wskaźnika (przekazanie przez referencję) nie modyfikuje liczby referencji.
Przekazanie wskaźnika do nowego właściciela (np. do funkcji) i wyrzucenie oryginału też nie zmienia liczby referencji.
Klonowanie jest potrzebne tylko jak zmienia się liczba właścicieli danych - tzn. pojawia się nowy właściciel danych wskazywanych przez wskaźnik, ale w praktyce to dość rzadkie sytuacje. Zwykle koszt utworzenia tego nowego właściciela (alokacja) jest większy niż skopiowanie wskaźnika.
Wspaniała gimnastyka tylko po to, by ułatwić kompilatorowi optymalizacje. Jak dla mnie to rozdwojenie typu pożyczanie kontra przesuwanie jest podobne do rozdwojenia sync vs async w oryginalnym artykule "what color is your function?" Rust nie dość, że koloruje funkcje względem sync/async to jeszcze dokłada kolory borrow/move. Dla prostych przykładów taka gimnastyka pewnie jest względnie prosta, ale dla bardziej skomplikowanych obstawiam, że może być nawet frustrująca. Nie pisałem na tyle w Ruście żeby mieć jakąś solidną opinię, więc nie będę ciągnął tematu. Ze swojej strony czekam na włączenie https://openjdk.java.net/projects/loom/ do głównej wersji Javy. Wtedy nie będzie ani rozjazdu sync/async ani borrow/move (w Golangu już tak jest, ale mnie do niego nie ciągnie). Sama wygoda :)
Między "może" a "musi" jest duża różnica. Akurat LFENCE i SFENCE na x86 to praktycznie noop, bo wszystkie dostępy są i tak koherentne i uporządkowane. Koszt występuje gdy linia cache jest faktycznie współdzielona między rdzeniami (i do tego nie musisz mieć wcale bariery - przy zwykłych aktualizacjach współdzielonego licznika też będziesz mieć duże opóźnienie). Koszt jest oczywiście niezerowy, bo atomic wyłącza pewne optymalizacje komplatora (np. out-of--order) i wymusza przesłania (nie można tak sobie licznika w rejestrze trzymać), ale dopóki dwa wątki nie zabijają się o wspólny licznik i nie robią milionów aktualizacji na sekundę, nie zauważysz narzutu.
W jednowątkowych zadaniach bez żadnego współdzielenia danych między rdzeniami też jest katastrofa wydajnościowa: https://www.phoronix.com/scan.php?page=article&item=lvi-attack-perf&num=5 (FLAC audio encoding, ZTCP to jest jednowątkowy test) Noopem bym tego nie nazwał.
3
Wspaniała gimnastyka tylko po to, by ułatwić kompilatorowi optymalizacje
Ale jaka gimnastyka? Dodanie & przed typem w sygnaturze metody aby uniknąć kopiowania to gimnastyka?
Poza tym patrzysz z perspektywy C++. Z perspektywy Rusta nie jest to żadna gimnastyka, tylko normalny sposób pracy z obiektami każdego typu (Rust jest domyślnie pass-by-move, a nie pass-by-copy jak C++). Nie da się niechcący skopiować wskaźnika. Aby skopiować wskaźnik, musisz się własnie nagimnastykować, tj. użyć na nim .clone().
A rozjazd między borrow/move jest potrzebny, bo semantycznie jest olbrzymia różnica. Taki sam rozjazd masz w Javie (i właściwie każdym języku) tylko jedyny sposób na udokumentowanie go to komentarze w kodzie. Przykład: Masz w Javie funkcję biorącą obiekt typu InputStream. Kto zamyka strumień? I co jak w JavaDoc nie ma o tym ani słowa?
Card tables w generacyjnych GC powinny rozwiązywać ten problem do pewnego stopnia: https://stackoverflow.com/que[...]able-and-writer-barrier-works
Dla każdego GC można znaleźć takie zadanie, z którym poradzi sobie słabo:
https://ionutbalosin.com/2019/12/jvm-garbage-collectors-benchmarks-report-19-12/
W jednowątkowych zadaniach bez żadnego współdzielenia danych między rdzeniami też jest katastrofa wydajnościowa: https://www.phoronix.com/scan[...]tem=lvi-attack-perf&num=5 (FLAC audio encoding, ZTCP to jest jednowątkowy test) Noopem bym tego nie nazwał.
Tylko że w tej mitygacji zdaje się że dodawany jest LFENCE po każdym przesłaniu danych z pamięci. To trochę częściej niż przy okazjonalnej aktualizacji licznika referencji.
Zauważ że nie we wszystkich benchmarkach zastosowanie LFENCE spowodowało tak drastyczny spadek wydajności - w wielu sytuacjach jest niezauważalne.
2
Ale jaka gimnastyka? Dodanie & przed typem w sygnaturze metody aby uniknąć kopiowania to gimnastyka?
Poza tym patrzysz z perspektywy C++. Z perspektywy Rusta nie jest to żadna gimnastyka, tylko normalny sposób pracy z obiektami każdego typu (Rust jest domyślnie pass-by-move, a nie pass-by-copy jak C++). Nie da się niechcący skopiować wskaźnika. Aby skopiować wskaźnik, musisz się własnie nagimnastykować, tj. użyć na nim .clone().
Gimnastyka polega na wyborze między przenoszeniem, pożyczaniem mut i nie mut (z zachowaniem zgodności lifetime'ów). Zmiana czegoś takiego w jednym miejscu może skutkować kaskadowymi zmianami w wielu innych miejscach. Inaczej rzecz biorąc: wybieranie między tymi trybami jest dodatkowym problemem podczas opracowywania architektury kodu. Ja bym jednak wolał się skupić na innych rzeczach. A równie dobrze można powiedzieć, że checked exceptions nie są problemem, bo co to jest jedno throws na metodę?
A rozjazd między borrow/move jest potrzebny, bo semantycznie jest olbrzymia różnica. Taki sam rozjazd masz w Javie (i właściwie każdym języku) tylko jedyny sposób na udokumentowanie go to komentarze w kodzie. Przykład: Masz w Javie funkcję biorącą obiekt typu InputStream. Kto zamyka strumień? I co jak w JavaDoc nie ma o tym ani słowa?
W typowym (statystycznie) kodzie zamyka się mniej więcej w tym samym miejscu co otwiera, np używając try-with-resources mamy otwieranie i zamykanie w jednej linijce. Rzadko kiedy widzę problemy (w sensie manifestujące się kiepską wydajnością czy błędami w runtime) z wyciekającymi zasobami.
Dla każdego GC można znaleźć takie zadanie, z którym poradzi sobie słabo:
Analogicznie: dla każdego alokatora można znaleźć zadanie, z którym poradzi sobie słabo. Już tu kiedyś robiłem testy alokatorów dla testu binarytrees z Benchmarks Game i jemalloc wypadał znacznie gorzej do tcmalloc. Alokatorów jest na pęczki i każdy pokazuje, że jest znacznie lepszy niż inne.
Tracing GC to mimo wszystko ciągle mocno zmieniający się temat. Java przełączyła się (w sensie domyślnego wyboru) na (dalej dynamicznie się rozwijający) G1 dopiero w 2017 roku: http://openjdk.java.net/jeps/248 Niskopauzowe GC przechodzą ze statusu experimental do production dopiero w nadchodzącej Javie 15: https://openjdk.java.net/jeps/377 https://openjdk.java.net/jeps/379 Sporo jeszcze testów przed nimi. Na razie koncentrują się na jakichś realnych benchmarkach typu SPECjbb, a nie mało realistycznych (w kontekście zastosowań biznesowych) Benchmarks Game.
Żeby przejście przez wszystkie destruktory i zwolnienie pamięci zajęło więcej niż przeciętne GC w Javie (nawet takie jak G1), które powiedzmy trwa ok 100 ms, to musiałbyś zwalniać hurtowo miliony obiektów. Poza tym takie zwolnienie i tak nie pauzuje innych wątków - pauzuje jeden wątek, ten zwalniający, natomiast pozostałe np. 47 rdzeni serwera dalej może wykonywać swoją pracę. A nawet w sytuacji gdyby to było problemem - jest banalne wyjście - zwalnianie w tle albo podzielenie zwalniania na paczki. Czyli jeden prosty do rozwiązania i niezbyt poważny problem (dealokacja) C++ został zastąpiony przez Javę innym, znacznie znacznie poważniejszym i znacznie trudniejszym do rozwiązania (pauzy GC).
Shenandoah GC ma mechanizm pacing: https://wiki.openjdk.java.net/display/shenandoah/Main#Main-FailureModes (szukaj: -XX:+ShenandoahPacing), który spowalnia wątek, który alokuje dużo, a reszta wątków (które alokują mało) może w tym czasie pracować z pełną prędkością.
Tylko że w tej mitygacji zdaje się że dodawany jest LFENCE po każdym przesłaniu danych z pamięci. To trochę częściej niż przy okazjonalnej aktualizacji licznika referencji.
Zauważ że nie we wszystkich benchmarkach zastosowanie LFENCE spowodowało tak drastyczny spadek wydajności - w wielu sytuacjach jest niezauważalne.
LFENCE after load ma największy wpływ na wydajność, prawie cały spadek jest przez to spowodowany:
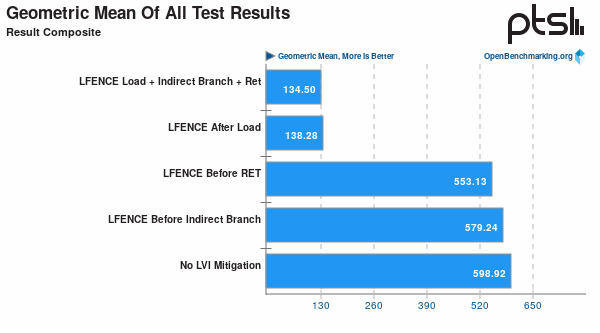
Tam gdzie wpływ był niewielki (Redis + memcached) prawdopodobnie IPC było bardzo niskie ze względu na opóźnienia na odczycie z pamięci (bo losowy dostęp do pamięci to główna czynność w tych programach), więc dodatkowe synchronizacje w potokach wykonawczych niewiele zmieniły. Ty napisałeś, że LOCK (silniejszy niż LFENCE) może być wykonywany razem z innymi instrukcjami (tak jak się to typowo dzieje w out-of-order CPU), ale nie jest to prawda i dobitnie to widać na wykresach.
2
Gimnastyka polega na wyborze między przenoszeniem, pożyczaniem mut i nie mut (z zachowaniem zgodności lifetime'ów).
Przesadzasz. W większości przypadków już "na dzień dobry" wiesz co potrzebujesz. Ogólne zasady są:
- referencja kiedy się da, o ile wiesz, że typ jest
Copy - mutowalna referencja jest dość oczywista kiedy
- przenoszenie jeśli ty chcesz być właścicielem (doh) lub jeśli jest to typ
Copy
Nie jest to trudne i bardzo szybko "wchodzi w krew", zwłaszcza, że kompilator Ciebie prowadzi.
Zmiana czegoś takiego w jednym miejscu może skutkować kaskadowymi zmianami w wielu innych miejscach.
Ale raczej tylko w obrębie samej funkcji lub ewentualnie miejsc gdzie tę funkcję wywołujesz. Ale jak wyżej, po chwili przyzwyczajenia, raczej rzadko kiedy jest to problemem.
Jak dla mnie to rozdwojenie typu pożyczanie kontra przesuwanie jest podobne do rozdwojenia sync vs async w oryginalnym artykule "what color is your function?" Rust nie dość, że koloruje funkcje względem sync/async to jeszcze dokłada kolory borrow/move.
No właśnie nie, bo zarówno funkcje sync/async jak i borrow/move są właściwościami typów, a nie funkcji. W Ruście zapis:
async fn foo() -> Bar { … }
Jest praktycznie równoważny zapisowi:
fn foo() -> impl Future<Bar> { … }
Dodatkowo w miejscu gdzie wywołujesz funkcję ewidentnie widzisz czy będzie to borrow czy move:
-
foo(val)- move -
foo(&val)- borrow -
foo(&mut val)- mut borrow
Więc po prawdzie nic nie jest przed Tobą ukryte i jeśli chcesz, to możesz "ręcznie" kontrolować wywołanie wszystkiego.
0
hauleth napisał(a):
Jak dla mnie to rozdwojenie typu pożyczanie kontra przesuwanie jest podobne do rozdwojenia sync vs async w oryginalnym artykule "what color is your function?" Rust nie dość, że koloruje funkcje względem sync/async to jeszcze dokłada kolory borrow/move.
No właśnie nie, bo zarówno funkcje sync/async jak i borrow/move są właściwościami typów, a nie funkcji. W Ruście zapis:
async fn foo() -> Bar { … }Jest praktycznie równoważny zapisowi:
fn foo() -> impl Future<Bar> { … }
Oba zapisy pokazują, że funkcje asynchroniczne mają inny kolor niż synchroniczne. Gdyby nie było rozdwojenia to nie byłoby potrzeby ani oznaczania czegoś async ani zwracania Future'ów.
4
hauleth napisał(a):
No właśnie nie, bo zarówno funkcje sync/async jak i borrow/move są właściwościami typów, a nie funkcji. W Ruście zapis:
async fn foo() -> Bar { … }Jest praktycznie równoważny zapisowi:
fn foo() -> impl Future<Bar> { … }
async to największy rak programowania asynchronicznego i kolorowanie funkcji jest strasznie słabe. Pół biedy, gdy jest to w języku od samego początku, ale jak dodaje się to w trakcie, to ma to bardzo wysoki koszt (C# jest tego świetnym przykładem). Ponadto to nie jest własność typu, tylko środowiska uruchomieniowego, kod biznesowy powinien być taki sam niezależnie od asynca, ale niestety tak się nie da, bo jest to zbyt magiczna zmiana i kompilator sam tego nie umie ogarnąć (może Loom w Javie pokaże, jak to powinno się zrobić porządnie).
Zaznaczam, że mówię o asyncu. Nie wiem, czy move/copy ma te same konsekwencje, ale widzę te same argumenty, co przy programowaniu asynchronicznym, a async jest przykładem, jak tego nie robić. Kolorowanie funkcji jest hakiem, nie dobrym rozwiązaniem.
0
hauleth napisał(a):
Przesadzasz. W większości przypadków już "na dzień dobry" wiesz co potrzebujesz. Ogólne zasady są:
- referencja kiedy się da, o ile wiesz, że typ jest
Copy- mutowalna referencja jest dość oczywista kiedy
- przenoszenie jeśli ty chcesz być właścicielem (doh) lub jeśli jest to typ
Copy
IMO to dobrze wygląda, gdy się pisze nowy kod, niestety z doświadczenia (C++) wydaje mi się, że zmiana funkcjonalności albo re-użycie często wiąże się z dużą liczbą szpachli. Przykładowo mamy kod, który używa jakieś struktury:
struct Foo {
s: String
}
oraz jesteśmy w takim miejscu w kodzie, gdzie mamy tylko dostęp do &str:
fn create_foo(s: &str) -> Foo {
Foo{s: s.to_owned()}
}
przez co musimy zrobić kopię stringu, co może być ciężkie. W jaki sposób użyć Foo tak, żeby raz trzymac String a raz &str? Zarówno Rust jak i C++ nie rozwiązują tego problemu w wygodny sposób
hauleth napisał(a):
No właśnie nie, bo zarówno funkcje sync/async jak i borrow/move są właściwościami typów, a nie funkcji. W Ruście zapis:
async fn foo() -> Bar { … }Jest praktycznie równoważny zapisowi:
fn foo() -> impl Future<Bar> { … }
Załóżmy, że jesteśmy na takiej głębokości wywołań, że najbliższa funkcja async jest 10 poziomów nad nami. W jaki sposób wywołać taki kod:
fn foo() {
task::sleep(Duration::from_secs(1)).await;
}
przecież to klasyczny przykład kolorowania funkcji.
0
W jaki sposób użyć Foo tak, żeby raz trzymac String a raz &str?
struct Foo<'a> {
s: Cow<'a, str>
}
fn foo_ref<'a>(s: &'a str) -> Foo<'a> {
Foo { s: s.into() }
}
fn foo_owned(s: String) -> Foo<'static> {
Foo { s: s.into() }
}
Załóżmy, że jesteśmy na takiej głębokości wywołań, że najbliższa funkcja async jest 10 poziomów nad nami. W jaki sposób wywołać taki kod:
fn foo() { task::sleep(Duration::from_secs(1)).await; }przecież to klasyczny przykład kolorowania funkcji.
Możesz albo zwrócić future:
fn foo() -> impl Future<()> {
task::sleep(Duration::from_secs(1))
}
Albo wymusić wywołanie tego w miejscu (do czego oczywiście potrzebujesz jakiegoś runtime do funkcji asynchronicznych):
use futures::executor::block_on;
fn foo() {
block_on(task::sleep(Duration::from_secs(1)))
}
1
Możesz albo zwrócić future:
Przecież wtedy zmienisz kolor funkcji i będzie musiał przerobić 10 poziomów funkcji z sync na async (czy tam z braku Future na dodany Future - na jedno wychodzi).
Albo wymusić wywołanie tego w miejscu (do czego oczywiście potrzebujesz jakiegoś runtime do funkcji asynchronicznych):
Na https://docs.rs/futures/0.3.5/futures/executor/fn.block_on.html znalazłem:
Run a future to completion on the current thread.
This function will block the caller until the given future has completed.
A więc blokuje rzeczywisty wątek i tym samym nie rozwiązuje problemu.
Golang rozwiązuje problem już teraz: https://gobyexample.com/select Wystarczy wstawić go przed wywołaniem funkcji i tyle, już jest nowa gorutyna uruchomiona. time.Sleep i inne funkcje czekające nie blokują rzeczywistego wątku systemowego tylko gorutynę, a gorutyn mogą być setki tysięcy bez zajeżdżania systemu.
Playground
std::borrow::Cow rozwiązuje jakieś problemy, ale co jeśli jestem w funkcji X, która ma pożyczony parametr i chciałbym coś na nim zrobić, ale z pomocnych gotowców jest tylko funkcja Y, która przyjmuje przenoszony argument? Obojętne czy zmienię funkcję X czy Y i tak będę musiał zmienić wszystkie funkcje, które korzystają z X czy Y (w sensie z tej którą zmienię) i być może zmiany spropagują się kaskadowo dalej.
Wracając do:
A rozjazd między borrow/move jest potrzebny, bo semantycznie jest olbrzymia różnica. Taki sam rozjazd masz w Javie (i właściwie każdym języku) tylko jedyny sposób na udokumentowanie go to komentarze w kodzie. Przykład: Masz w Javie funkcję biorącą obiekt typu InputStream. Kto zamyka strumień? I co jak w JavaDoc nie ma o tym ani słowa?
O ile w przypadku zasobów taki mechanizm jest być może trochę pomocny, o tyle w przypadku obiektów całkowicie zawartych w pamięci procesu (czyli zwykłych danych niebędących uchwytami do żadnego zasobu) w niczym nie pomaga pod względem poprawności, bo nie ma znaczenia kto i jak długo po utracie osiągalności je usunie. Tego typu zmiennych (tzn tych zwykłych danych) jest zdecydowanie najwięcej w kodzie (obstawiam, że tak z 99%+).
1
A więc blokuje rzeczywisty wątek i tym samym nie rozwiązuje problemu.
A jak inaczej chcesz to rozwiązać?
Golang rozwiązuje problem już teraz: https://gobyexample.com/select Wystarczy wstawić
goprzed wywołaniem funkcji i tyle, już jest nowa gorutyna uruchomiona.time.Sleepi inne funkcje czekające nie blokują rzeczywistego wątku systemowego tylko gorutynę, a gorutyn mogą być setki tysięcy bez zajeżdżania systemu.
Tak, tylko to wymaga runtime, którego Rust stara się unikać. Dodatkowo przywiązuje ciebie do jednej implementacji asynchroniczności. Jeśli chcesz odpalić to w osobnym wątku to możesz użyć std::thread::spawn by odpalić wątek systemowy i to "rozwiąże" problem. Funkcje asynchroniczne w Ruscie są czymś zupełnie innym. Jednak to dalej sprowadza się do tego samego - Go ma runtime, przez co nie nadaje się do niektórych zastosowań, Rust tego nie ma, ale w zamian masz pewne rzeczy, które trzeba rozwiązywać inaczej.
std::borrow::Cowrozwiązuje jakieś problemy, ale co jeśli jestem w funkcji X, która ma pożyczony parametr i chciałbym coś na nim zrobić, ale z pomocnych gotowców jest tylko funkcja Y, która przyjmuje przenoszony argument?
Jeśli funkcja Y może bez problemu pracować na argumencie, który jest pożyczony, to znaczy, że bez sensu go przenosi. Jeśli musi go przenieść, to i tak musiałbyś go skopiować. Więc tak czy siak, coś zmienić, przynajmniej częściowo, będzie trzeba. Na ten przykład:
fn bar(s: String) { … }
fn foo(s: &str) { bar(s.to_owned()) }
Obojętne czy zmienię funkcję X czy Y i tak będę musiał zmienić wszystkie funkcje, które korzystają z X czy Y (w sensie z tej którą zmienię) i być może zmiany spropagują się kaskadowo dalej.
Niekoniecznie, bo np. jeśli funkcja wcześniej przyjmowała jako argument wartość przeniesioną to można zamienić to w typ, który będzie akceptował oba (std::borrow::Borrow), przykład.
w niczym nie pomaga pod względem poprawności
Chyba, że masz wiele procesów, które równolegle mogą modyfikować te dane. Jeśli jednak mówisz o strukturach złożonych z samych typów prostych, to zawsze masz Copy w Ruście, które spowoduje, że większość tych problemów zniknie.
nie ma znaczenia kto i jak długo po utracie osiągalności je usunie
Niby tak, ale to powoduje niedeterminizm, który w części aplikacji jest mocno niepożądany. Na ten przykład Discord z dokładnie tego powodu porzucił Go w jednym z serwisów.
1
hauleth napisał(a):
A więc blokuje rzeczywisty wątek i tym samym nie rozwiązuje problemu.
A jak inaczej chcesz to rozwiązać?
Golang rozwiązuje problem już teraz: https://gobyexample.com/select Wystarczy wstawić
goprzed wywołaniem funkcji i tyle, już jest nowa gorutyna uruchomiona.time.Sleepi inne funkcje czekające nie blokują rzeczywistego wątku systemowego tylko gorutynę, a gorutyn mogą być setki tysięcy bez zajeżdżania systemu.Tak, tylko to wymaga runtime, którego Rust stara się unikać. Dodatkowo przywiązuje ciebie do jednej implementacji asynchroniczności. Jeśli chcesz odpalić to w osobnym wątku to możesz użyć
std::thread::spawnby odpalić wątek systemowy i to "rozwiąże" problem. Funkcje asynchroniczne w Ruscie są czymś zupełnie innym. Jednak to dalej sprowadza się do tego samego - Go ma runtime, przez co nie nadaje się do niektórych zastosowań, Rust tego nie ma, ale w zamian masz pewne rzeczy, które trzeba rozwiązywać inaczej.
Gorutyna/corutyna(w przypadku innych języków) vs wątek systemowy to ogromna różnica w konsumpcji zasobów. Ale fakt, ten runtime wyklucza pewne zastosowania, co przykładowo potwierdzili twórcy Fuschia.
0
A jak inaczej chcesz to rozwiązać?
Przecież napisałeś o tym tuż poniżej.
Tak, tylko to wymaga runtime, którego Rust stara się unikać. Dodatkowo przywiązuje ciebie do jednej implementacji asynchroniczności. Jeśli chcesz odpalić to w osobnym wątku to możesz użyć std:
:spawn by odpalić wątek systemowy i to "rozwiąże" problem. Funkcje asynchroniczne w Ruscie są czymś zupełnie innym.
Project Loom https://openjdk.java.net/projects/loom/ wprowadza virtual threads jako dodatek obok istniejących rzeczywistych wątków (tzn mapowanych 1:1 na wątki systemowe). Nie trzeba rezygnować z jednego na rzecz drugiego, bo można mieć oba rozwiązania. W dodatku podobno nawet schedulery dla wirtualnych wątków będzie można samemu oprogramować.
Jednak to dalej sprowadza się do tego samego - Go ma runtime, przez co nie nadaje się do niektórych zastosowań, Rust tego nie ma, ale w zamian masz pewne rzeczy, które trzeba rozwiązywać inaczej.
Z perspektywy systems programming language kompromis jest zrozumiały, ale z perspektywy języka ogólnego przeznaczenia jest totalnie chybiony.
Jeśli funkcja Y może bez problemu pracować na argumencie, który jest pożyczony, to znaczy, że bez sensu go przenosi. Jeśli musi go przenieść, to i tak musiałbyś go skopiować. Więc tak czy siak, coś zmienić, przynajmniej częściowo, będzie trzeba.
Trzeba kopiować, bo destruktory są wbite w stałe miejsca w kodzie, tam gdzie lifetime się kończy. W Javie/ Ruby/ Python/ etc czymkolwiek z GC nie trzeba nic kopiować. Skąd mam wiedzieć gdzie kopiowanie ma sens? Muszę w głowie sobie zasymulować program i stwierdzić, gdzie kopiowanie będzie miało najmniejszy narzut.
Chyba, że masz wiele procesów, które równolegle mogą modyfikować te dane. Jeśli jednak mówisz o strukturach złożonych z samych typów prostych, to zawsze masz Copy w Ruście, które spowoduje, że większość tych problemów zniknie.
Jestem zwolennikiem programowania funkcyjnego, więc używam niemutowalnych struktur danych i nie mam specjalnie dużych problemów z komunikacją międzywątkową.
Niby tak, ale to powoduje niedeterminizm, który w części aplikacji jest mocno niepożądany. Na ten przykład Discord z dokładnie tego powodu porzucił Go w jednym z serwisów.
Przepisali jednego, reszta została. W artykule jest ciekawy fragment:
We kept digging and learned the spikes were huge not because of a massive amount of ready-to-free memory, but because the garbage collector needed to scan the entire LRU cache in order to determine if the memory was truly free from references. Thus, we figured a smaller LRU cache would be faster because the garbage collector would have less to scan. So we added another setting to the service to change the size of the LRU cache and changed the architecture to have many partitioned LRU caches per server.
Brzmi jakby GC w Golangu nie miało CardTable dzięki któremu można odśmiecać młodą generację bez przechodzenia starej podczas cyklu GC. W każdym razie GC dalej żwawo ewoluują i coraz lepiej sobie radzą.
1
hauleth napisał(a):
Tak, tylko to wymaga runtime, którego Rust stara się unikać. Dodatkowo przywiązuje ciebie do jednej implementacji asynchroniczności.
Ani jedno, ani drugie. Da się to zrobić na samej bibliotece standardowej (i nie trzeba mieć wsparcia systemu operacyjnego), ponadto może być wiele implementacji.
Najprostszy przykład zarysowujący ideę: async vs sync różni się kontekstem działania, a kontekst to po prostu monada. Nic nie stoi na przeszkodzie, żeby każda funkcja zwracała M[T], gdzie M jest kontekstem sync/async, a T było konkretną wartością (to jest tak naprawdę zwracanie future). Różnica jest taka, że zamiast pozbywać się M w metodach synchronicznych można zwracać Id[T], które to wykonywałoby synchronicznie.
Drugim elementem jest cooperative scheduling, które przy wywołaniach z future i tak jest, bo metoda w którymś momencie musi skonfigurować kontynuację czy callback, więc to i tak jest robione w pewnym momencie explicite.
Teraz wystarczy dorzucić do tego kompilator, który ładnie opakuje wszystko w jakieś do-syntax (jak w Haskellu) i odpowiednio poklei wywołania map na dobrej monadzie (future lub Id), którą gdzieś tam na samej górze sobie zapniemy przez DI/implicit/jawnie.
Inne podejście to oczywiście fibery czy jakieś zielone wątki od systemu, CPS (który fajnie działa w językach do tego przygotowanych, na przykład w JS). Ale nie trzeba do tego runtime'u.
2
Najprostszy przykład zarysowujący ideę: async vs sync różni się kontekstem działania, a kontekst to po prostu monada. Nic nie stoi na przeszkodzie, żeby każda funkcja zwracała M[T], gdzie M jest kontekstem sync/async, a T było konkretną wartością (to jest tak naprawdę zwracanie future). Różnica jest taka, że zamiast pozbywać się M w metodach synchronicznych można zwracać Id[T], które to wykonywałoby synchronicznie.
Drugim elementem jest cooperative scheduling, które przy wywołaniach z future i tak jest, bo metoda w którymś momencie musi skonfigurować kontynuację czy callback, więc to i tak jest robione w pewnym momencie explicite.
Teraz wystarczy dorzucić do tego kompilator, który ładnie opakuje wszystko w jakieś do-syntax (jak w Haskellu) i odpowiednio poklei wywołania map na dobrej monadzie (future lub Id), którą gdzieś tam na samej górze sobie zapniemy przez DI/implicit/jawnie.
Ale dokładnie tak działa Rust. Mamy "monadę" Future<Output = T> oraz kompilator to ładnie opakowuje w "do-syntax" w miejscach gdzie używamy async. Następnie musisz takie Future<Output = T> przekazać jawnie "na samej górze" do jakiegoś runtime, które wywoła "map" (w tym przypadku Future::poll).
Inne podejście to oczywiście fibery czy jakieś zielone wątki od systemu, CPS (który fajnie działa w językach do tego przygotowanych, na przykład w JS). Ale nie trzeba do tego runtime'u.
Co wymaga konkretnego systemu operacyjnego w takim wypadku. Czyli de facto wymieniamy runtime na wymaganie całego OSa. Dalej w "niskopoziomowych" zastosowaniach jest to trudne.
Skąd mam wiedzieć gdzie kopiowanie ma sens?
Jeśli Ty chcesz się przejmować niszczeniem obiektu, wtedy ma sens. Przykłady:
- Builder gdzie chcesz zabronić użycia go ponownie
- Funkcja hashująca, w której nie chcesz by ktoś przypadkowo użył jej ponownie (szczególny przypadek powyższego)
- Kiedy chcesz zmodyfikować strukturę i zwrócić zmodyfikowaną (np. funkcje sortujące)
- Pracujesz tylko na strukturach
Copy
W przeciwnym wypadku prawie zawsze chcesz mieć referencję. Przykładowo nie ma sensu pisać funkcji, która przyjmuje jako argument String bo zawsze jest lepiej użyć &str (ze względu na autodereferencję). Praktycznie nigdy nie ma sensu jako argument przyjmować Vec<T>, bo można przyjąć &[T] i wyjdzie na to samo w większości przypadków.
Jestem zwolennikiem programowania funkcyjnego, więc używam niemutowalnych struktur danych i nie mam specjalnie dużych problemów z komunikacją międzywątkową.
Rust ma typy wewnętrznie mutowalne (np. Rc), więc częściowo problem nie znika.
Project Loom https://openjdk.java.net/projects/loom/ wprowadza virtual threads jako dodatek obok istniejących rzeczywistych wątków (tzn mapowanych 1:1 na wątki systemowe).
No tak, ale założenia Rusta są trochę inne niż Javy. Nie rozumiem o czym teraz dyskutujemy, bo całość miałabyć o RC vs M&S a teraz dyskutujemy o tym jak rozwiązać M:N threading w różnych językach. No tak, Java może to rozwiązać inaczej niż Rust, bo ma inne założenia (np. zakłada, że mamy runtime, które może być praktycznie dowolnie duże). Inne zastosowania i zupełnie inny cel powstania tych języków. To chyba oczywiste, że w takim przypadku będzie się w takich językach pisało inaczej.
Bo jeśli mamy dyskutować o M:N threading to wejdę z Erlangiem i wszystkie Javy czy Go mogą się tutaj schować, bo trochę im zajmie ogarnięcie tego na takim samym poziomie jak Erlang to wspiera.