W C# od zawsze, a w C++ od jakiegoś czasu możliwa jest deklaracja zmiennej bez podawania typu w przypadku, gdy można jednoznacznie wykryć, jaki typ powinna mieć ta zmienna. Do tego służy słowo var i auto.
Moim zdaniem to jest bardziej mało użyteczny bajer niż bardzo pożądana funkcjonalność. Jedyną zaletą, jaką widzę, jest to, że nie trzeba zmieniać definicji zmiennej, jak nagle zajdzie potrzeba zmiany typu zwracanej wartości funkcji, która nadaje tej zmiennej wartość (właśnie po tym kompilator dedukuje, jaki tym ma mieć ta zmienna), jednakże takie przypadki są bardzo sporadyczne.
Zauważyłem, że automatyczne wykrywanie typu zmiennej stało się bardzo popularne w jezykach z sztywnymi typami zmiennych wyposażonymi w taką możliwość.
Jednak dostrzegłem olbrzymią wadę, która dla mnie przesłania opisaną wyżej korzyść. Weźmy przykład z życia wzięty. Niedawno potrzebowałem zrobić coś takiego, że program rozpoczyna odmierzanie czasu i wykonuje jakieś obliczenia, potem program wykonuje dalszy kod, albo po wykonaniu obliczeń, albo minimum 3 sekundy od momentu rozpoczęcia obliczeń. W C# do tego celu może służyć System.Diagnostic.Stopwatch, potrzebuję tego, ale w C++.
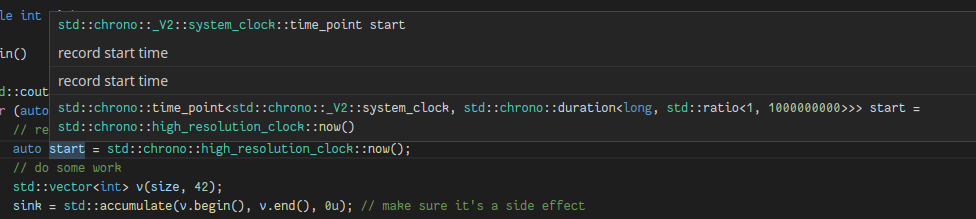
No to wpisuję w Google c++ stopwatch i na jednym z pierwszych miejsc jest ta strona: https://www.pluralsight.com/blog/software-development/how-to-measure-execution-time-intervals-in-c-- . To jest praktycznie to, czego szukam, tylko trochę przerobić i zrezygnować z przeliczania na liczbę sekund (wystarczy zliczać wewnętrzne jednostki). Jak widać, mamy auto start = std::chrono::high_resolution_clock::now();. Chcę zobaczyć, jakie ma metody obiekt start, Qt Creator nie chce podpowiadać, bo nie wie, jakiego typu jest start, to się okaże przy kompilacji. Przechodzę do definicji metody now() i trafiam do skomplikowanego kodu z biblioteki, w której też nie widać, jakiego typu wartość zwraca ta funkcja.
Nie poddaję się, wpisuje w Google std::chrono::high_resolution_clock::now() i trafiam na https://en.cppreference.com/w/cpp/chrono/high_resolution_clock/now i właściwie nadal nie wiem, czym jest zmienna start. Dopiero z https://www.cplusplus.com/reference/chrono/high_resolution_clock/now/ dowiaduję się, że jest to std::chrono::high_resolution_clock::time_point.
Dopiero, jak w kodzie zmieniłem auto na std::chrono::high_resolution_clock::time_point to IDE już sam umiał podpowiedzieć funkcje i do tego wiedziałem o czym czytać, jakbym chciał z tą zmienną dalej coś robić.
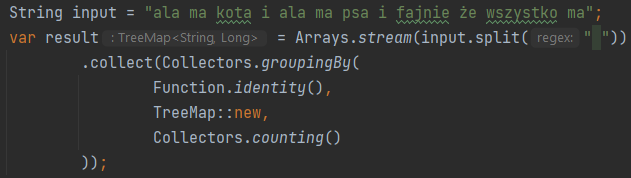
Inny przykład. Jakiś czas temu, w C# potrzebowałem przejrzeć slownik typu System.Collection.Dictionary<int,string>. Wpisuje w google coś, co kieruje mnie do kodu tego pokroju:
Dictionary<int, string> X;
foreach (var item in X)
{
}
Kod się kompiluje, ale Visual Studio nie umie podpowiedzieć, czym jest item ani co on zawiera. Dopiero, jak po kilku dalszych poszukiwaniach i próbach doczytałem, ze jest to KeyValuePair<inst,string>, to problem się rozwiązał i kompilator podpowiedział, że item ma właściwości key i value. Nieraz miałem do czynienia z innymi podobnymi obiektami, które też mają klucz i wartość, jednak innego typu i problem się powtarzał.
Co przesądza o tym, że programiści tak chętnie korzystają z auto i var mimo takich niedogodności z tym związanych? Argument, że słowo auto jest krótsze od słowa std::chrono::high_resolution_clock::time_point nie przemawia do mnie. A jeżeli nie wiadomo, jaki będzie docelowy typ i możliwe, że trzeba zmienić, albo nazwa typu jest za dluga, to przecież w C++ jest typedef, które służy do takich celów, ewentualnie też jest #define.