Witajcie.
Piszę do Was w sprawie problemów jakie mam z silnikiem MSSQL w wersji 2016.
Korzystamy z ERPa CDN Optima XL. Od początku roku zaczął się nam problem z wydajnością SQLa, nie bardzo mam z czym to powiązać i dlatego nie mając pomysłu postanowiłem napisać do Was.
Otóż, maszyna na której stoi SQL jest zwirtualizowana, to jest hiper-v server core pracujący w klastrze FO. Całość jest obsługiwana przez nowiutką SASową macierz HP 12G all flash.
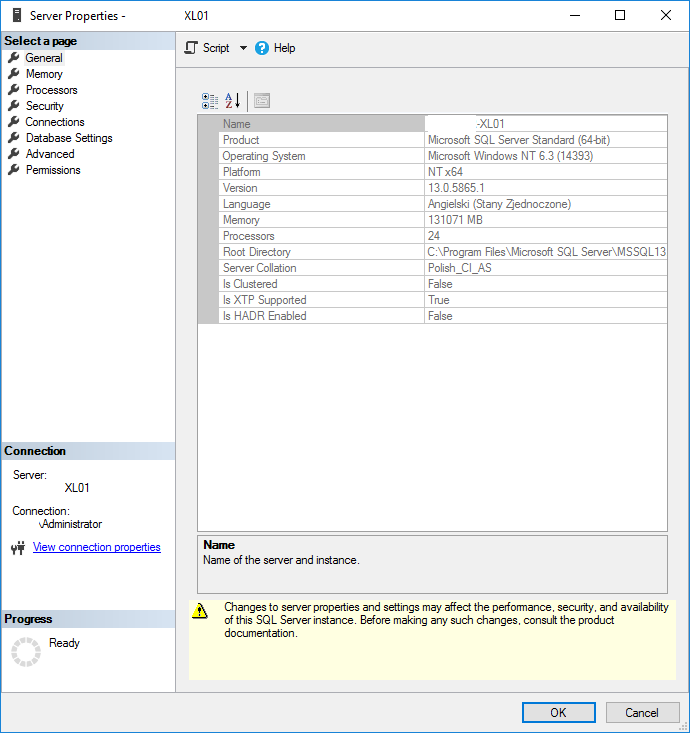
Maszyna wirtualna stoi na Windows 2016 server standard i ma przydzielone 128 GB RAM z czego wykorzystuje może 30 GB.
Problem wygląda tak, że kiedy równolegle wykonujemy „stresujące” dla bazy operacje, silnik bazy danych zdaje się blokować przetwarzanie kolejnych żądań do czasu zakończenia tych które są uruchamiane okresowo. Innymi słowy wygląda to tak, że podczas normalnej pracy w ERP wszystko chodzi przyzwoicie, kiedy jednak chcemy rozpocząć proces zamykania zleceń zaczyna się problem, w czasie zamykania poszczególnych zleceń nie można nic innego robić na bazie. Jeszcze w grudniu ubiegłego roku taki problem nie występował, nie bardzo rozumiem co się mogło stać.
Szerzej mówiąc wygląda to tak, że jeśli chodzi o Activity Monitor z SSMS podczas zamykania ZP i pracy w XL-u. Procesor Time normalnie nie wskakuje maks powyżej 30%.
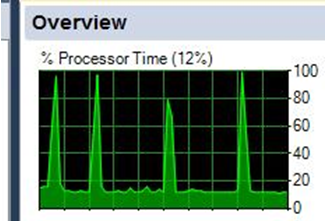
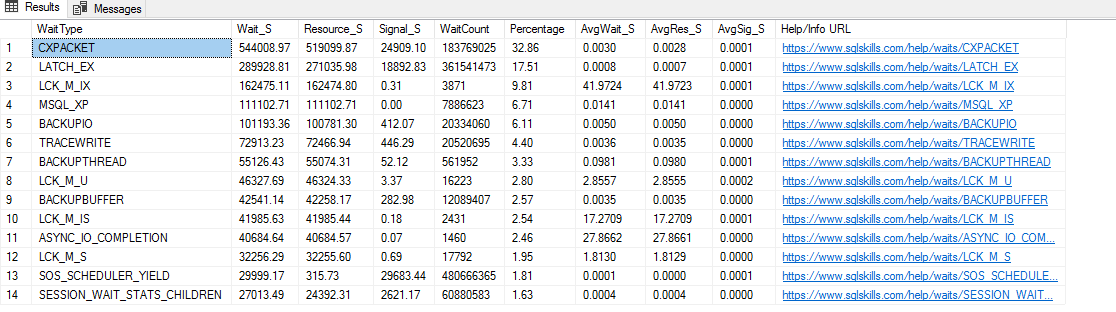
Przy zamykaniu zleceń ciągle ma Piki do 100% obciążenia. tak samo wygląda na serwerze w monitorze wydajności.
Waiting Tasks wzrasta masakrycznie szybko….
Database I/O nie ma żadnego obciążenia.
Batch Requests/sec też rosną strasznie…
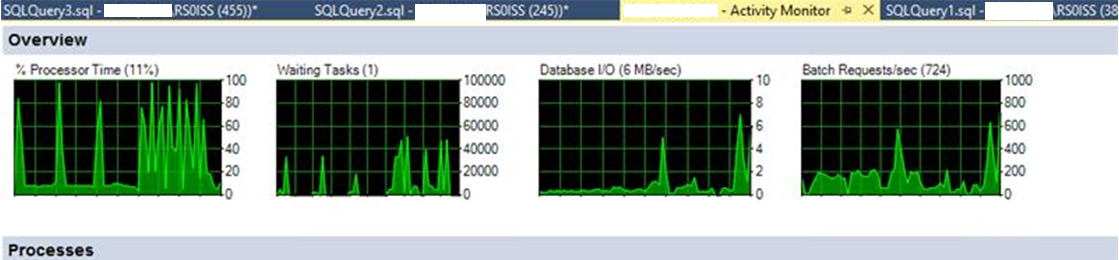
Próbowaliśmy już przenieść wirtualkę na fizyczne dyski SSD po za macierz, bez efektu. Czyli to nie macierz. Na najmocniejszym serwerze z trzech w klastrze zostawiliśmy tylko tą maszynę, też to niewiele dało. To tak wygląda jakby SQL się zapchał i prawie zatrzymał.
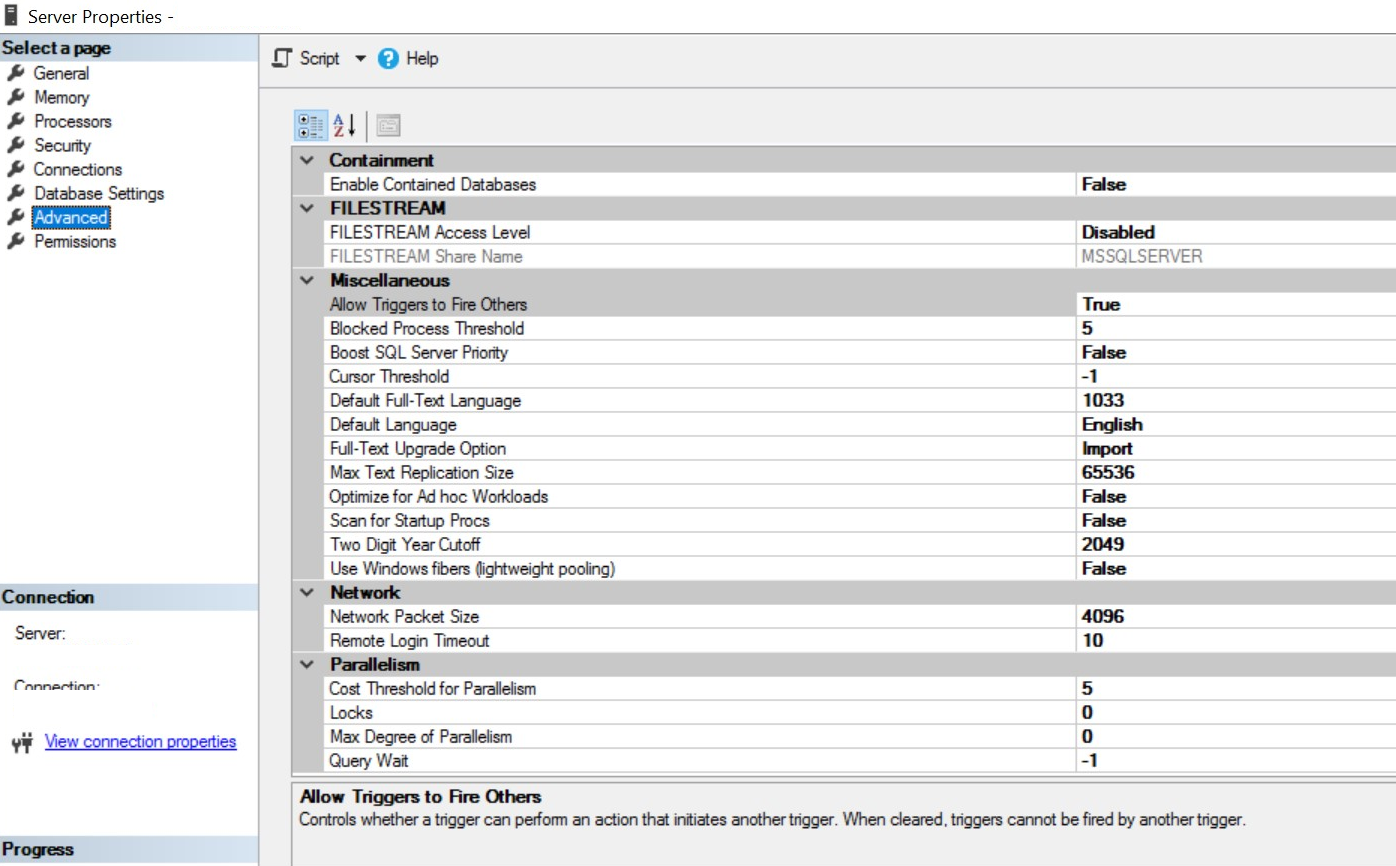
Zastanawiam się, czy w konfiguracji SQL NIE MA czegoś takiego co limituje ilość jednoczesnych operacji, faktem jest, że w czasie zamykania zleceń serwer ma więcej pracy, ale nie jest to na tyle dużo aby całkowicie zaprzestać możliwości pracy pozostałych pracowników w systemie.
Podpowiecie coś ? Z góry dziękuję
 ), a na pewno nie zaszkodzi.
), a na pewno nie zaszkodzi.